According to Wikipedia Cardiovascular is the leading cause of death globally [1]. It is a combination of different heart and blood vessels such as heart diseases, heart attacks, stroke, heart failures, arrhythmia, heart valve problems, etc. High blood pressure, high cholesterol, diabetes, physical inactivity are some major causes for increasing the risk of getting this disease. By minimizing behavioral risk factors such as smoking, unhealthy diet, using alcohol, and physical inactivity this disease can be prevented.
If people can be aware in advance about this disease before it turns into a more risk level, we can minimize the number of deaths and high-risk level patients at a considerable amount. With the aid of development in Machine Learning and high computational power have driven exponential advancement in Artificial intelligence in the field of medicine, where people can use these technologies and come up with a model and do the predictions to identify the likelihood of people getting this disease in earliest stages.
In this article, a machine learning model has proposed and implemented to identify the likelihood of a person is having this disease or not by concentrating on factors like factual information, results of medical examinations, and patient information gathered from an online dataset [2]. K Nearest Neighbors algorithm which is a well-known and well-performing classification algorithm was used to implement this model.
Algorithm Selection
K Nearest Neighbors is a simple algorithm but works incredibly in practice that stores all the available cases and classifies the new data or case based on a similarity measure. It suggests that if the new point added to the sample is similar to the neighbor points, that point will belong to the particular class of the neighbor points. In general, KNN algorithm uses in search applications where people looking for similar items. K in the KNN algorithm denotes the number of nearest neighbors of the new point which needed to be predicted.
KNN algorithm is also known as a lazy learner because there is less learning phase of the model due to it’s pretty fast learning ability. Instead, it memorizes the training dataset and all the work happens at the time the prediction is requested.
How does the algorithm work?
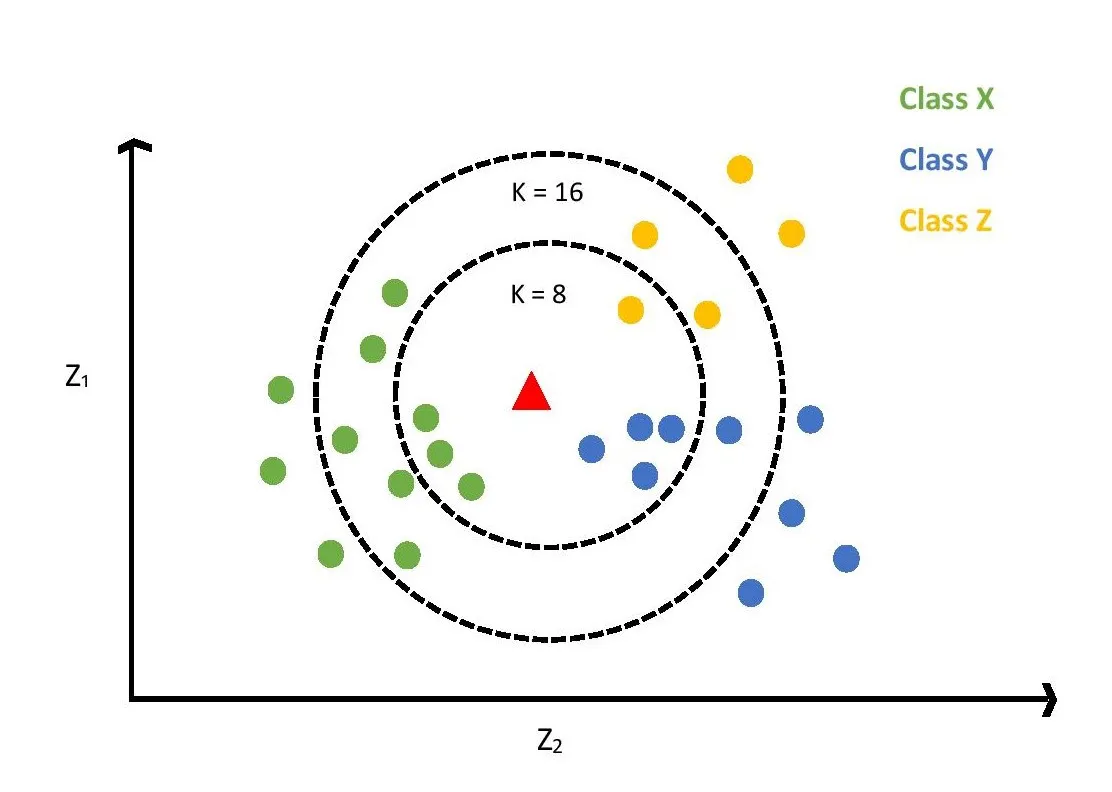
When we add a new point to a dataset using the KNN algorithm we can predict which class the new point is belonging to. In order to start the prediction, the very first thing we need to do is selecting the value of K. According to fig 1, points with green color belong to class X, points with blue color belong to class Y and yellow color pints belong to class Z. When K=8, we need to select 8 neighbor points that have the least distance to the new point which is representing by the triangle. As demonstrated in fig 1 when K=8 new point is close to one yellow point, three green points, and four blue points. Since we have a majority of blue points, in this case, we can say that for K=8 the new point belongs to class Y.
Moving on ahead if K=16, we have to look for 16 different points which are closest to the new points. After calculating the distance, it is found that when K=16 new point is closer to three yellow points, five blue points, and eight green points. Therefore, we can say that when K=16 the new point belongs to class X.
In order to find the best K value, we can use a cross-validation technique to test several values of K. I will show you how to use the cross-validation technique to find the best K value in this article. In order to find the least distance between neighbor points, we can use either Euclidean distance or Manhattan distance. In the Euclidean distance, it will take the straight line distance between two points in a Euclidean space while the Manhattan distance will calculate the distance between real vectors using the sum of their absolute difference.
#elbow-method #cardiovascular-disease #k-nearest-neighbours #data-science