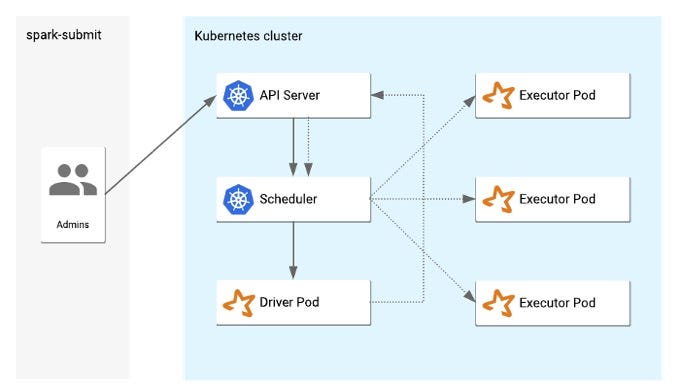
Apache Spark
Apache Spark has become the prime tool for handling and managing big data. With the added advantage of being a completely open-source technology and a very active community, it has long replaced Hadoop’s Map Reduce. One of the reasons for that is simplicity, both in management and usage. It provides support for Scala, Python and R. Since Python is the most popular language for data science, I will be focusing on PySpark. However, not many changes are required to use any of the other two languages.
#spark #python #apache-spark #pyspark #kubernetes
2.60 GEEK