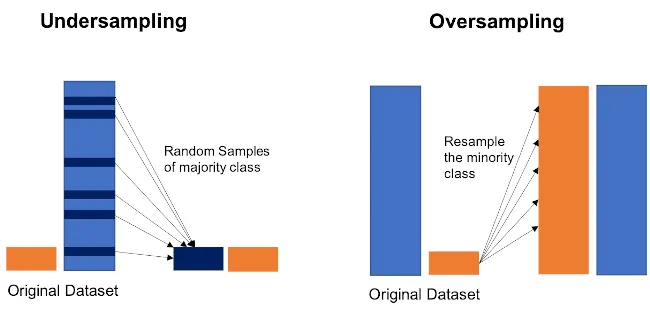
In classification machine learning problems(binary and multiclass), datasets are often imbalanced which means that one class has a higher number of samples than others. This will lead to bias during the training of the model, the class containing a higher number of samples will be preferred more over the classes containing a lower number of samples. Having bias will, in turn, increase the true-negative and false-positive rates. Hence to overcome this bias of the model we need to make the dataset balanced containing an approximately equal number of samples in all the classes.
In this article, I’ll be discussing the way to achieve balanced datasets using various techniques, as well as compare them.
For demonstration, I’ve taken the Pima Indians Diabetes Database by UCI Machine Learning from Kaggle. Get the dataset from here. This is a binary classification dataset. Dataset consists of various factors related to diabetes – Pregnancies, Glucose, blood pressure, Skin Thickness, Insulin, BMI, Diabetes Pedigree, Age, Outcome(1 for positive, 0 for negative). ‘Outcome’ is the dependent variable, rest are independent variables.
#developers corner #bias #classification #machine learning