The bias-variance dilemma is a widely known problem in the field of machine learning. Its importance is such, that if you don’t get the trade-off right, it won’t matter how many hours or how much money you throw at your model.
In the illustration above, you can get a feel for what bias and variance are as well as how they can affect your model performance. The first chart shows a model (blue line) that is underfitting the training data (red crosses). This model is biased, because it “assumes” the relationship between the independent variable and the dependent variable is linear when it is not. Plotting a scatter plot of the data is always helpful as it will reveal the true relationship between the variables — a quadratic function would fit the data “just right” (second chart). The third chart is a clear example of overfitting. The high complexity of the model allows it to fit the data very closely — too closely. Although this model might perform really well on the training data, its performance on the test data (i.e. data it has never seen before) will be much worse. In other words, this model suffers from high variance, which means that it won’t be good at making predictions on data it has never seen before. Because the main point of building a machine learning model is to be able to accurately make predictions on new data, you should be focused on making sure it will generalise well to unseen observations, rather than maximising its performance on your training set.
What can you do if your model performance is not so good?
There are several things you can do:
- Get more data
- Try a smaller set of features (reduce model complexity)
- Try adding/creating more features (increase model complexity)
- Try decreasing the regularisation parameter λ (increase model complexity)
- Try increasing the regularisation parameter λ (decrease model complexity)
The question now is: “how do I know which of those things to try first?”. The answer is: “well, it depends.”. And it basically depends on whether your model is suffering from high bias or from high variance.
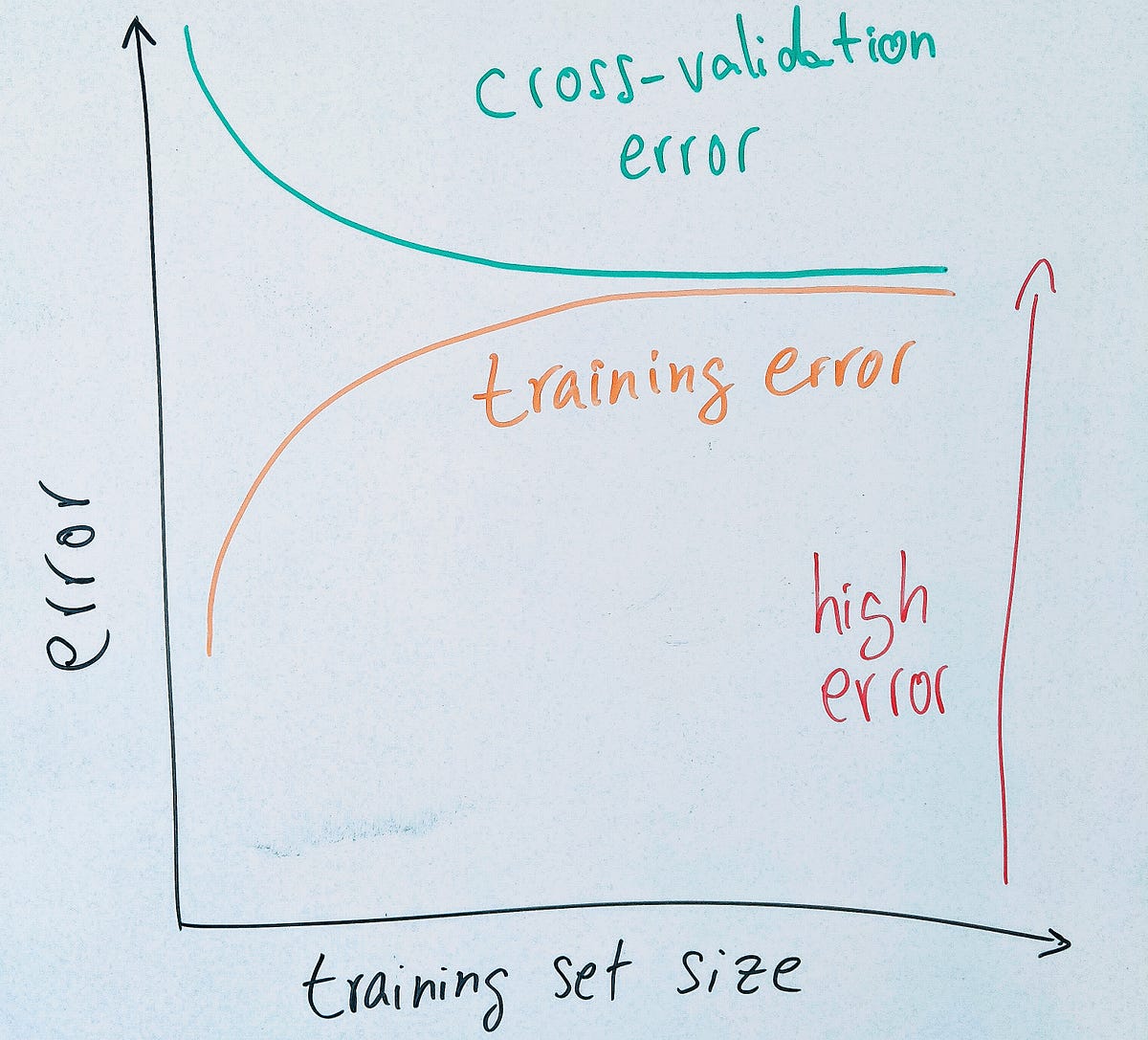
The issue here, you might be wondering, is: “ok, so my model is not performing as expected… but how do I know if it has a bias problem or a variance problem?!”. Learning curves!
#machine-learning #learning-curve #data-science #statistics