Why we need sessions
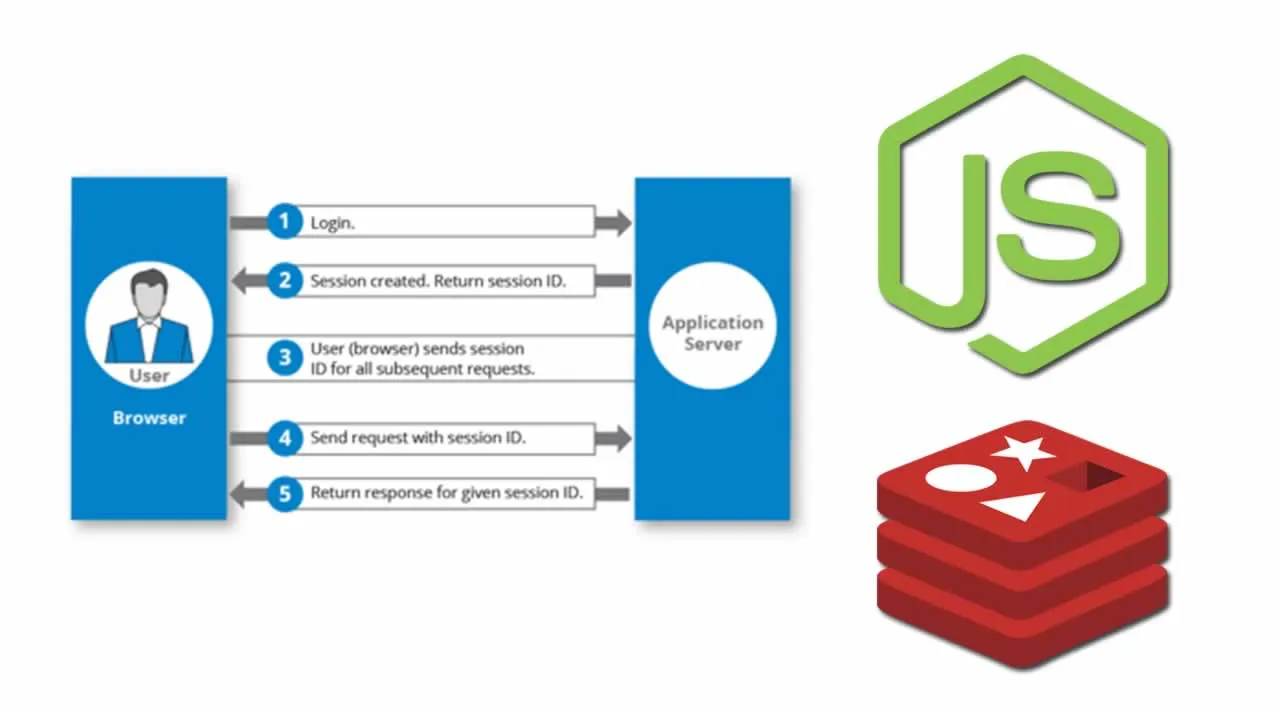
The classic Hypertext Transfer Protocol (HTTP) is a stateless tool. This means every request that is sent from a single client is interpreted by the Web server independently and is not related to any other request. There is no inbuilt mechanism for the server to remember a specific user from different multiple requests, which also makes it impossible for the server to know if each request originated from the same user.
HTTP Sessions
Session tracking enables you to track a user’s progress over multiple servlets or HTML pages, which, by nature, are stateless. A session is defined as a series of related browser requests that come from the same client during a certain time period. Session tracking ties together a series of browser requests — think of these requests as pages — that may have some meaning as a whole, such as a shopping cart application.
There are few types of session storing techniques
- Memory (single-server, non-replicated persistent storage)
- File system persistence
- JDBC persistence
- Cookie-based session persistence
- In-memory replication
Here we are using the Memory (single-server, non-replicated persistent storage) to manage sessions. When you use memory-based storage, all session information is stored in memory and is lost when you stop and restart. Better to use a external persistence storage.
We are creating the session in our session store and the session ID is sent back to the client in a Cookie. Then this Cookie can be passed to server with each and every request to identify the particular client.
#nodejs #redis #expressjs #session-management