To read this paper in document format click here.
ABSTRACT
NLP (Natural Language Processing) is a branch of artificial intelligence geared towards allowing computers to interact with humans through an understanding of human (natural) languages. This study focuses on training an NLP model to be used in a sentiment analysis on Big Tech policy by scraping and analyzing reactions to Big Tech articles linked on Reddit, using PRAW, an Reddit-specific web scraping API. Posts were scraped from the r/politics subreddit, a forum dedicated to the discussion of American politics. I found that there was a somewhat substantial skew towards support for policies intended to inhibit Big Tech power.
MOTIVATION
In the wake of Congress’s Big Tech Hearing [1], many social media activists began to release anti-Big Tech posts and graphics, as well as the tangentially-related blasts against billionaires and their role in wealth inequality. However, every post would always host a controversial comments section between those against sweeping antitrust moves and those supportive of them. This prompted me to wonder the true sentiment on Big Tech’s market power.
METHODS
By web scraping Reddit with the PRAW API a list of this year’s top 100 articles about Big Tech was compiled from the r/politics subreddit. Since these articles all loosely involved policies intended to inhibit FAANG market power, using NLP to analyze the top-level comments for each post could provide an adequate representation of sentiment towards big tech. Each comment could be reasonably inferred to have a noticeable negative or positive sentiment towards a Big Tech policy, since I used a subreddit dedicated to discussing American politics.
Both the Reddits scraping and the machine learning model were coded in a single file in this Google Colab (the code can be run in the environment). More in-depth annotations with the code are provided as well. All machine learning code was written using the TensorFlow library.
The model was trained on the TensorFlow IMDb Dataset, an open-source dataset of 50,000 movie reviews split into 25,000 reviews intended for training and 25,000 reviews intended for validation. These were automatically randomized upon initialization. This dataset was inferred to be applicable to the Reddit comment data because reviews and political discussion often consist of a similar pool of opinionated words. To validate this assumption, I manually cluster-sampled and rated 20% of the Reddit posts and their comments to compare to the algorithm’s prediction later on.
After experimenting with training the neural network under a supervised learning system and comparing it against the validation data, it was determined that a good model would consist of a sequential model with the following layers:

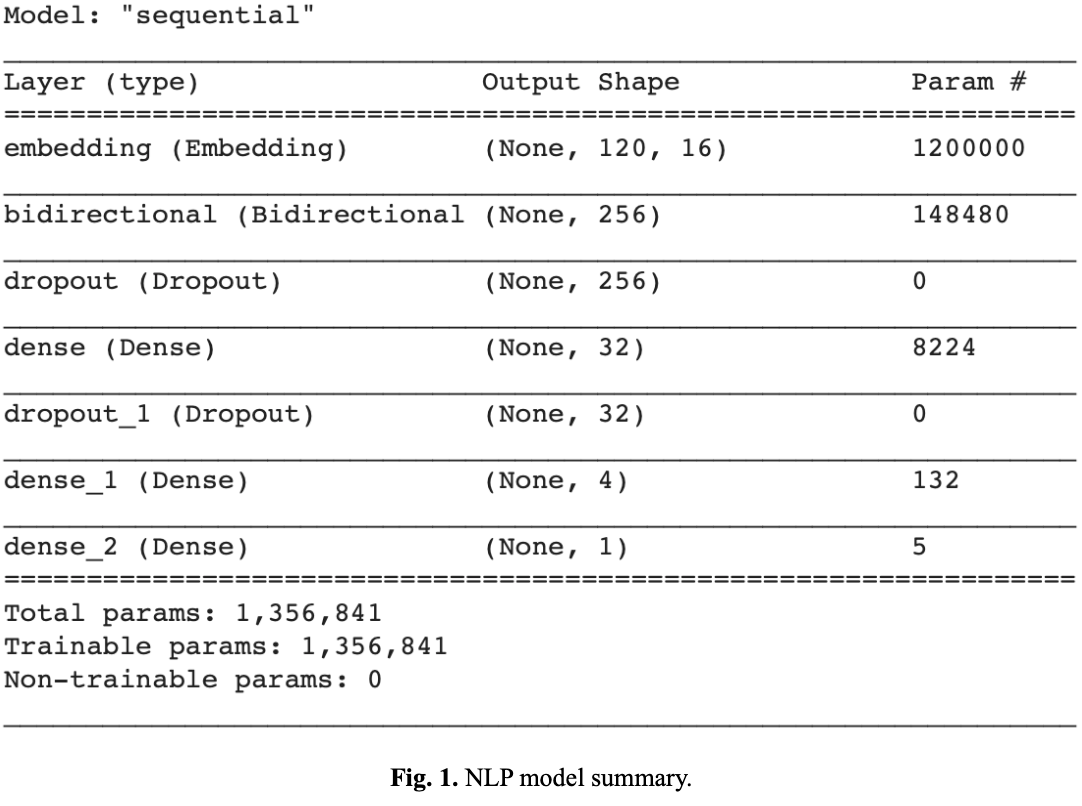
This model would ultimately consist of 1,356,841 trainable parameters (see Fig. 1.). The binary_crossentropy loss function was used because the intention was to categorize the comments into an either negative or positive reaction towards each article. The adam optimizer was also used because it works particularly well with NLP models. The metric used was just left as accuracy.
During testing, the model was run across 10 epochs, noting the accuracy, val_accuracy, loss, and val_loss across the epochs. The changes were graphed using the matplotlib library:
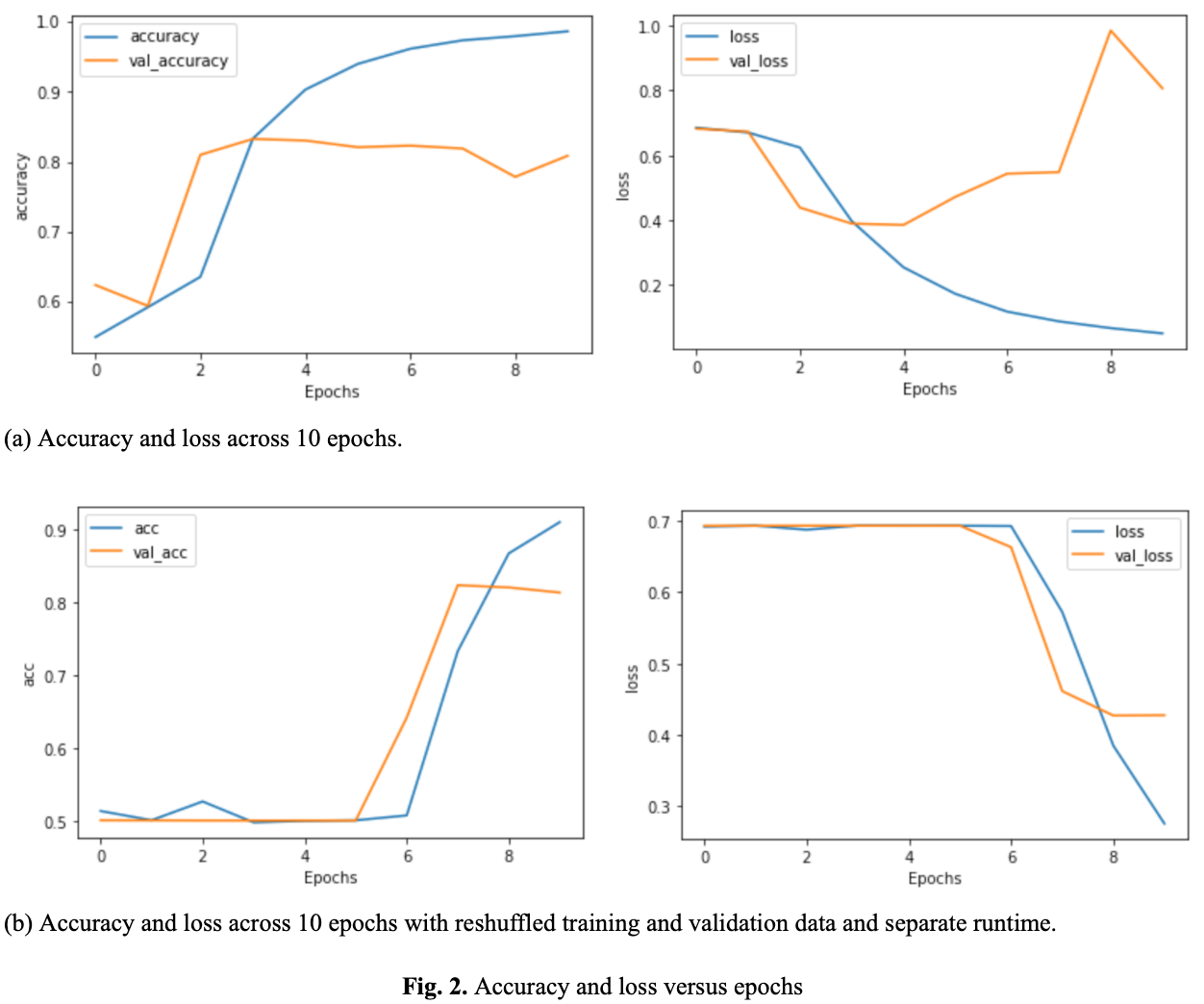
By comparing the accuracy and loss versus epochs graphs (see Fig. 2.), it was evident that maximizing val_accuracy while minimizing val_loss would require writing an abrupt callback. Since v_al_accuracy_ had roughly plateaued by 0.93 accuracy and val_loss had hit a minimum, the training should have been called back under the 0.93 accuracy. Beyond 0.93 accuracy, the val_loss would increase, showing a risk of overfitting, for little to no gain in val_accuracy, with the possibility of decreasing val_accuracy. Thus, the callback was written to stop the training once the 0.93 accuracy benchmark was hit. Depending on the training process, the benchmark could be hit between 4 epochs (see Fig. 2. (a)) to 10 epochs (see Fig. 2. (b)).
#data-science #big-tech #machine-learning