- So you are at a party where you c̶a̶n̶’̶t̶ ̶s̶e̶e̶m̶ ̶t̶o̶ ̶s̶h̶u̶t̶ ̶u̶p̶ ̶ are telling everyone enthusiastically about how AI will change the world and you know that because you are an _AI Enthusiast _or a Machine Learning Practitioner or whatever fancy-sounding title you use to describe yourself. Then, someone who reads the newspaper every now and then asks you “I don’t really get the difference between Deep Learning and traditional Machine Learning. What is the difference between Deep Learning and (classical) Machine learning?”. You give some handwavy explanation about how neurons in a neural network are based on the human brain blah blah blah…an answer that leaves people unconvinced and leaves you embarrassed.
Hierarchical Compositionality
Deep Learning model architectures tend to be based on the idea that the world around exhibits hierarchical compositionality. In simple terms, every complex thing in the world is made up of simple building blocks and these simple building blocks are in turn made up of even simpler building blocks. This is analogous to how in Chemistry, a compound is made up of molecules and molecules in turn are made of atoms or in a business context, how the organisation is made up of departments, departments are made of teams and teams are made of employees.
Likewise, in an image, pixels form edges, edges form shapes, shapes form textons (a complex combination of shapes), textons form objects and objects form a complete image. In the case of Natural Language Processing, characters form words, words form phrases, phrases form sentences, sentences form paragraphs. By mirroring this hierarchical nature of the data through their architectures, Deep Learning models are able to learn how the simpler parts form the complex whole by modeling the hierarchical relationships in the data.
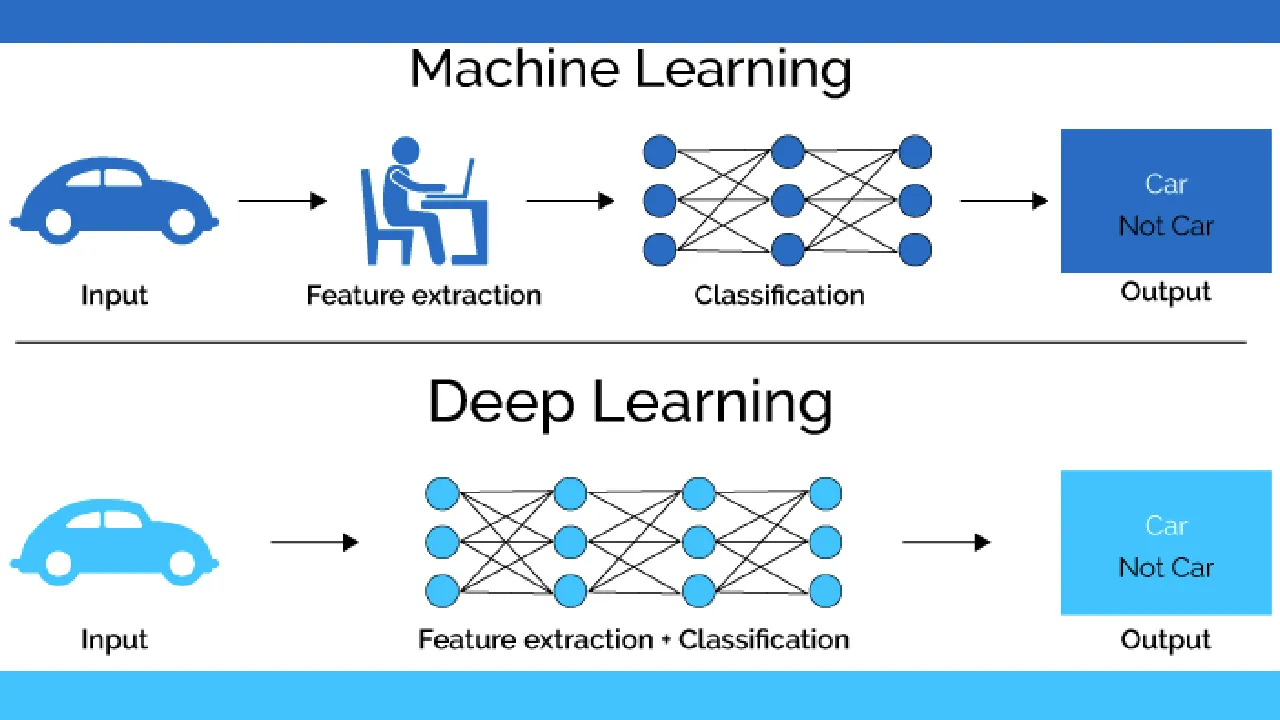
In a traditional Machine Learning approach, an expert would get involved to hand-pick these low-level features and then hand-engineer the extraction of these low-level features, which could then be fed to model such as a SVM classifier. Not only is this process cumbersome, choosing and defining the features involves some degree of interpretative decision making , which is prone to bias and loss of information due to oversimplification of the data. Deep Learning, on the other hand, takes the raw data as its input and automatically learns the hierarchical elements and their relationships through the training process.
Distributed Representation
In a neural network, neurons work together to learn representations of the data. A single neuron, by itself, neither encodes everything nor does it really encode one particular thing. Just as how in an orchestra no single instrument can truly express the full richness of a musical composition, in a neural network, the complex representation of data is learnt by the whole network of neurons working together by passing information back and forth.
Contrarily, in a traditional Machine Learning approach, to classify the image of a cat as such, parts of the model pipeline would be configured to detect specific features of a cat. For example, there could be a component detecting whiskers, another component detecting a tail and so on. In Deep Learning, however, no single neuron is specifically configured to look for whiskers or a tail.
This trait of distributed representation actually gives Deep Learning an edge in certain situations. One such situation is transfer learning. For example, a deep learning model trained for classifying cat breeds could easily be used for dog breed classification with some simple fine-tuning.
End-to-end Learning
The idea of Deep Learning applying the learning process in an end-to-end manner was implied heavily in the aforementioned points. However, this distinction is non-trivial and bears repeating as its own separate distinguishing characteristic of Deep Learning. In Deep Learning, the learning process is applied to every step of the process — the model takes the raw data as input, performs feature extraction by learning the feature representations and learns the parameters to perform the necessary task such as classification. In fact, the process is _so _end-to-end that the line between feature extraction and parameter optimisation for a task such as classification is very blur.
#machine-learning #artificial-intelligence #deep-learning #data-science