The Snowflake Data Warehouse has an excellent reputation as an analytics platform for blisteringly fast query performance but without indexes. So, how can you tune the Snowflake database to maximize query performance? This article explains the top three techniques to tune your system to maximum throughput, including data ingestion, data transformation, and end-user queries.
Snowflake Query Performance
One of my favorite phrases is: What problem are we trying to solve? As techies, we often launch into solutions before we even understand the true nature of the problem. The performance issues on any analytics platform generally fall into one of three categories:
- Data Load Speed: The ability to load massive volumes of data as quickly as possible.
- Data Transformation: The ability to maximize throughput, and rapidly transform the raw data into a form suitable for queries.
- Data Query Speed: This aims to minimize the latency of each query and deliver results to business intelligence users as fast as possible.
1. Snowflake Data Loading
Avoid Scanning Files
The diagram below illustrates the most common method of bulk loading data into Snowflake, which involves transferring the data from the on-premise system to cloud storage, and then using the COPY command to load to Snowflake.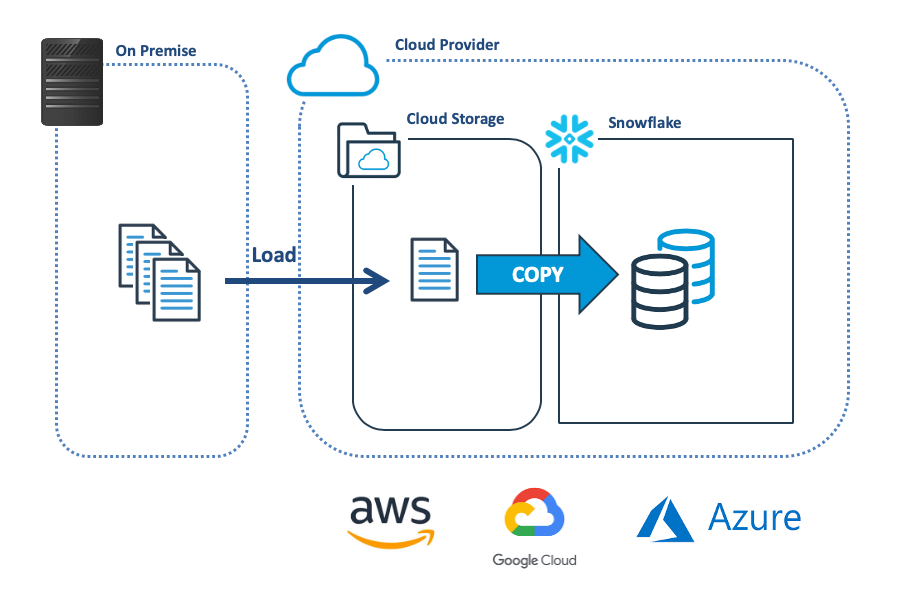
Before copying data, Snowflake checks the file has not already been loaded, and this leads the first and easiest way to maximize load performance by limiting the COPY command to a specific directory. The code snippet below shows a COPY using a range of options.
SQL
1
-- Slowest method: Scan entire stage
2
copy into sales_table
3
from @landing_data
4
pattern='.*[.]csv';
5
6
-- Most Flexible method: Limit within directory
7
copy into sales_table
8
from @landing_data/sales/transactions/2020/05
9
pattern='.*[.]csv';
10
11
-- Fastest method: A named file
12
copy into sales_table
13
from @landing_data/sales/transactions/2020/05/sales_050.csv;
14
While the absolute fastest method is to name a specific file, indicating a wildcard is the most flexible. The alternative option is to remove the files immediately after loading.
Size the Virtual Warehouse and Files
The diagram below illustrates a common mistake made by designers when loading large data files into Snowflake, which involves scaling up to a bigger virtual warehouse to speed the load process. In reality, scaling up the warehouse has no performance benefit in this case.
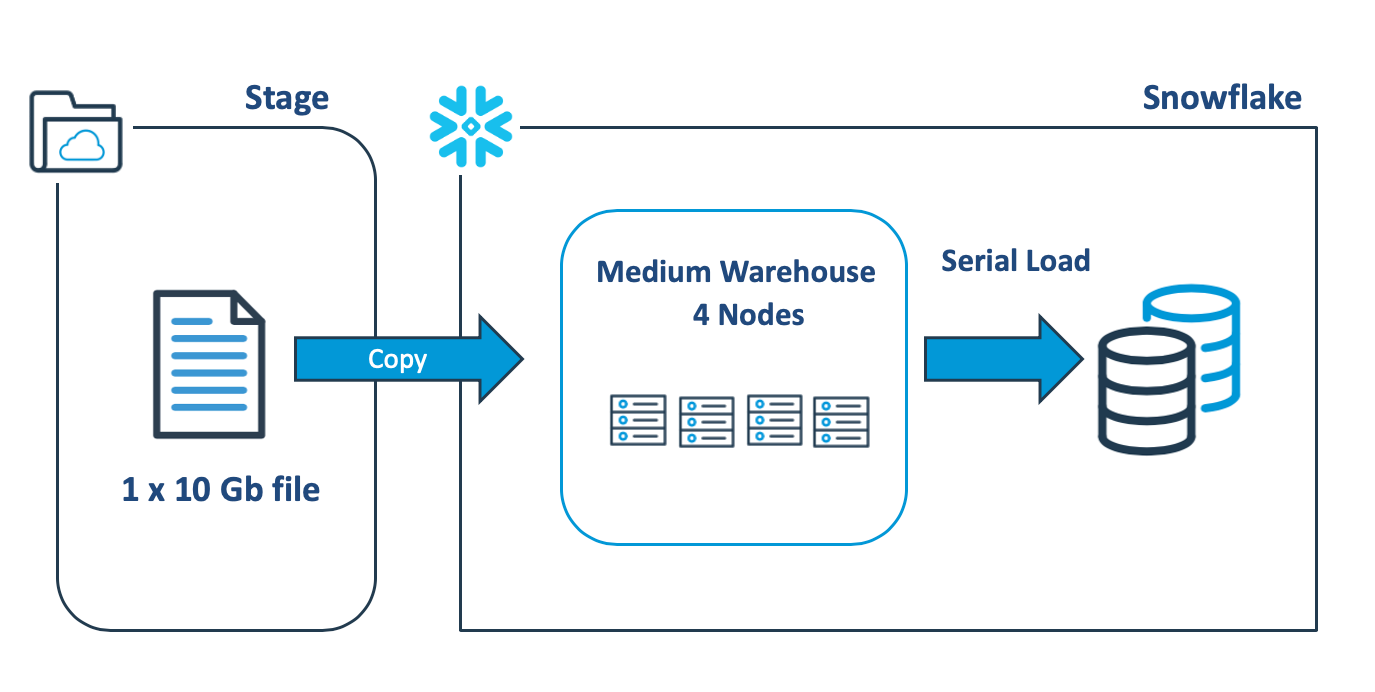
The above COPY statement will open the 10Gb data file and sequentially load the data using a single thread on one node, leaving the remaining servers idle. Benchmark tests demonstrate a load rate of around 9 Gb per minute, which is fast but could be improved.
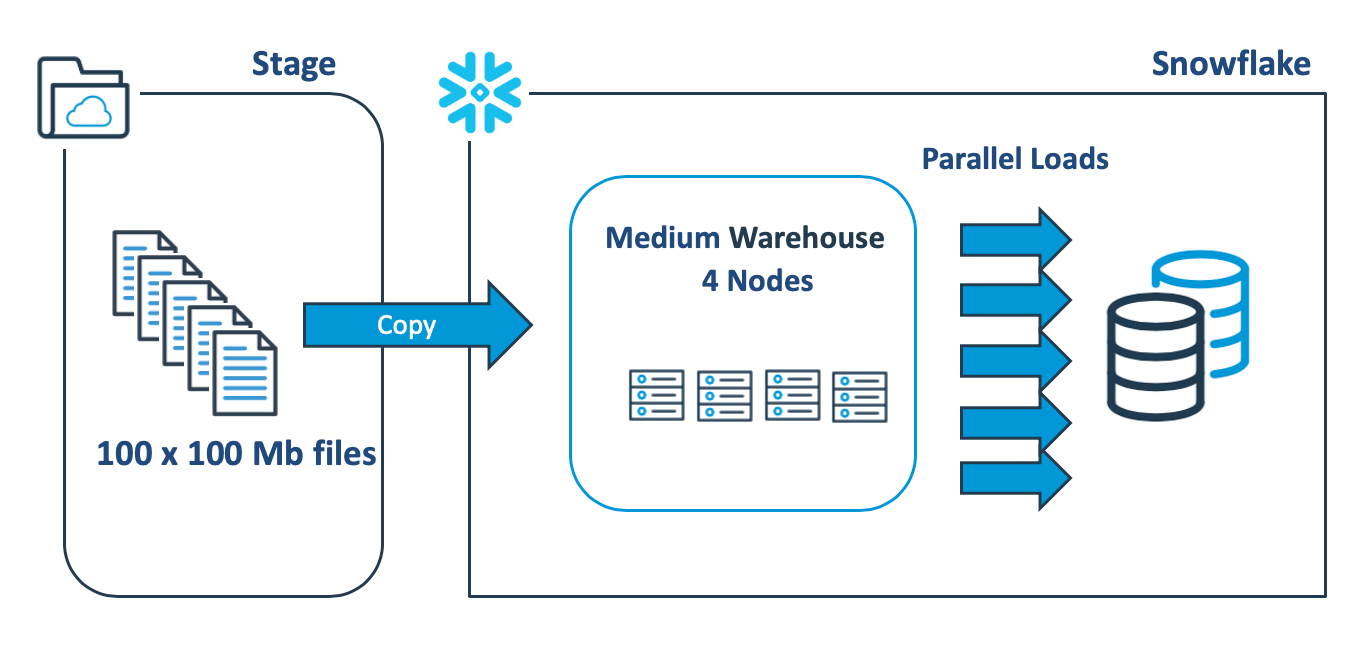
The diagram below illustrates a better approach, which involves breaking up the single 10Gb file into 100 x 100Mb files to make use of Snowflake’s automatic parallel execution.
#database #data warehouse #performance tuning #snowflake computing
