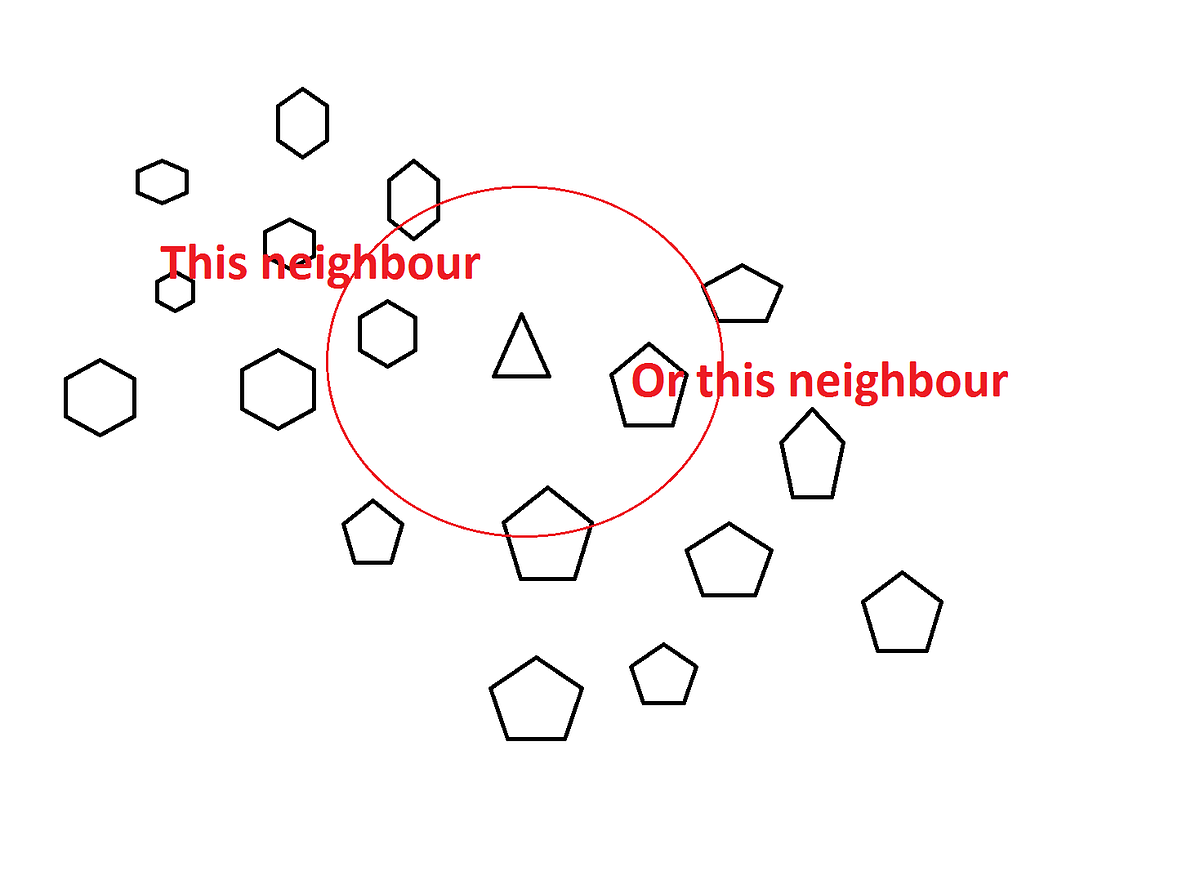
KNN: K Nearest Neighbor is one of the fundamental algorithms in machine learning. Machine learning models use a set of input values to predict output values. KNN is one of the simplest forms of machine learning algorithms mostly used for classification. It classifies the data point on how its neighbor is classified.
KNN classifies the new data points based on the similarity measure of the earlier stored data points. For example, if we have a dataset of tomatoes and bananas. KNN will store similar measures like shape and color. When a new object comes it will check its similarity with the color (red or yellow) and shape.
K in KNN represents the number of the nearest neighbors we used to classify new data points.
How do I choose K?
In real-life problems where we have many points the question arises is how to select the value of K?
Choosing the right value of K is called parameter tuning and it’s necessary for better results. By choosing the value of K we square root the total number of data points available in the dataset.
a. K = sqrt (total number of data points).
b. Odd value of K is always selected to avoid confusion between 2 classes.
When is KNN?
a. We have properly labeled data. For example, if we are predicting someone is having diabetes or not the final label can be 1 or 0. It cannot be NaN or -1.
b. Data is noise-free. For the diabetes data set we cannot have a Glucose level as 0 or 10000. It’s practically impossible.
c. Small dataset.
How does KNN work?
We usually use Euclidean distance to calculate the nearest neighbor. If we have two points (x, y) and (a, b). The formula for Euclidean distance (d) will be
d = sqrt((x-a)²+(y-b)²)
We try to get the smallest Euclidean distance and based on the number of smaller distances we perform our calculation.
Let’s try KNN on one database to see how it works. The data can be extracted from https://github.com/adityakumar529/Coursera_Capstone/blob/master/diabetes.csv.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
#knn-algorithm #data-science #knn #towards-data-science #machine-learning #algorithms