Random Forest is a mainstream AI algorithm that has a place with the regulated learning strategy. It might be used for both Classification and Regression issues in ML. It depends on the idea of ensemble learning, which is a cycle of joining numerous classifiers to tackle an intricate issue and to improve the presentation of the model.
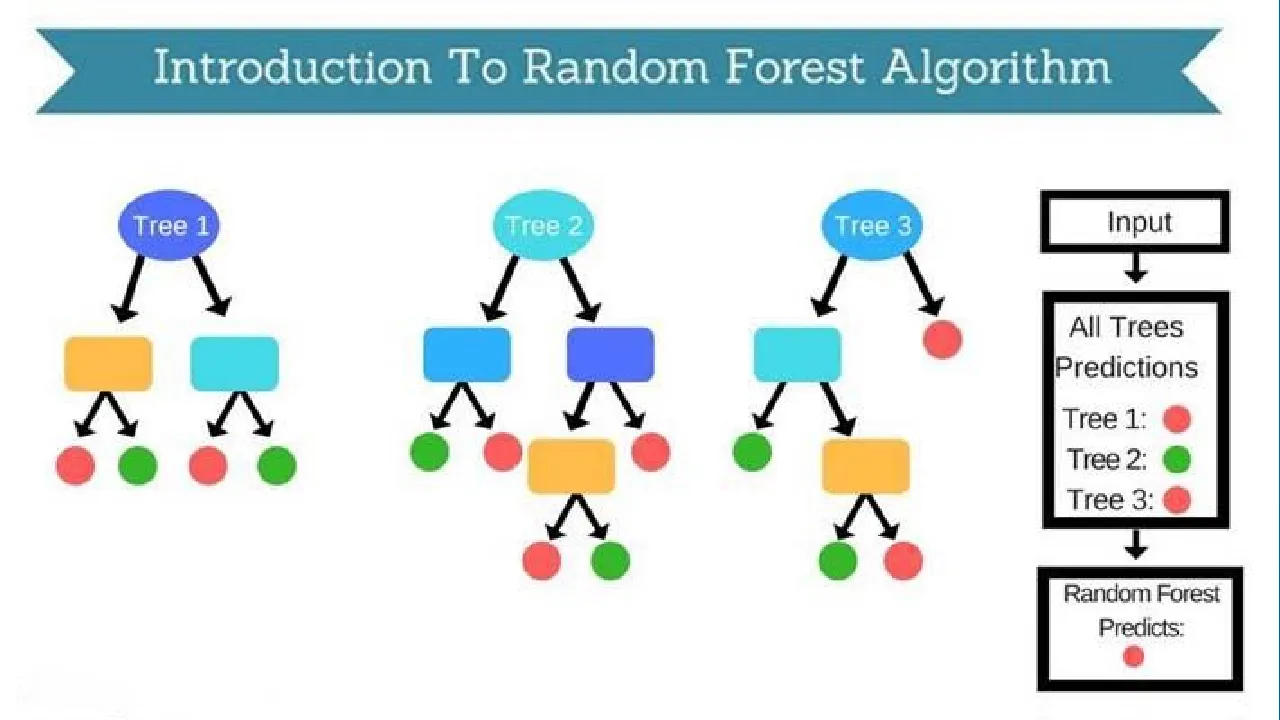
As the name proposes, “Random Forest is a classifier that contains different decision trees on various subsets of the given dataset and takes the typical to improve the perceptive precision of that dataset.”
Instead of relying upon one decision tree, the random forest takes the figure from each tree and subject it to the larger part votes of desires, and it predicts the last yield. The more noticeable number of trees in the forest prompts higher exactness and forestalls the issue of overfitting.
**Presumptions for Random Forest **
Since the random forest consolidates various trees to anticipate the class of the dataset, it is conceivable that some choice trees may foresee the right yield, while others may not. Yet, together, all the trees anticipate the right yield. In this way, beneath are two presumptions for a superior random forest classifier:
- There should be some real qualities in the component variable of a dataset with a goal that the classifier can foresee precise outcomes as opposed to a speculated result.
- The forecasts from each tree must have low connections.
#artificial intelligence #random forest #introduction to random forest algorithm #random forest algorithm #algorithm