Introduction to Statistics
Statistics is among the most widely used and important disciplines of study that has proved to be indispensable in numerous domains such as Engineering, Psychology, Operational Research, Chemometrics, etc. Among the most dependent statistical discipline is the field of Data Science and this is the reason that for having an in-depth understanding of it, Statistics should be understood in great detail.
The term statistics is often misunderstood, and this is the reason that first, we need to get a very clear understanding of it. In order to understand basic statistics for data science, we first have to understand get familiarized with a few basic terminologies.
Population
A population can be understood as the total number of individual humans, other organisms, or any other object that makes up a whole. With this understanding, the underlying conditions are very important in determining the number of objects/items, etc. that will form the population. If we talk about the Apple Laptops manufactured in the month of September 2013 in a particular factory of China, then the number may not be as large as the total number of computers presently active in the world. Thus, the population may or may not be large as this depends on the conditions which define what is to be considered as the population.
Parameter
Numerous mathematical calculations can be performed on the population such as finding the most common item or value occurring in the population or finding the average etc. All such arithmetic operations that allow us to define the population in simple numeric digits are provided with the term parameter. For example, if we want to know the average age of all the people living in a village. If there are 200 people in that village whose age we are able to capture successfully then this average age will be called a parameter. It will be called so as its value has been calculated using the complete population information.
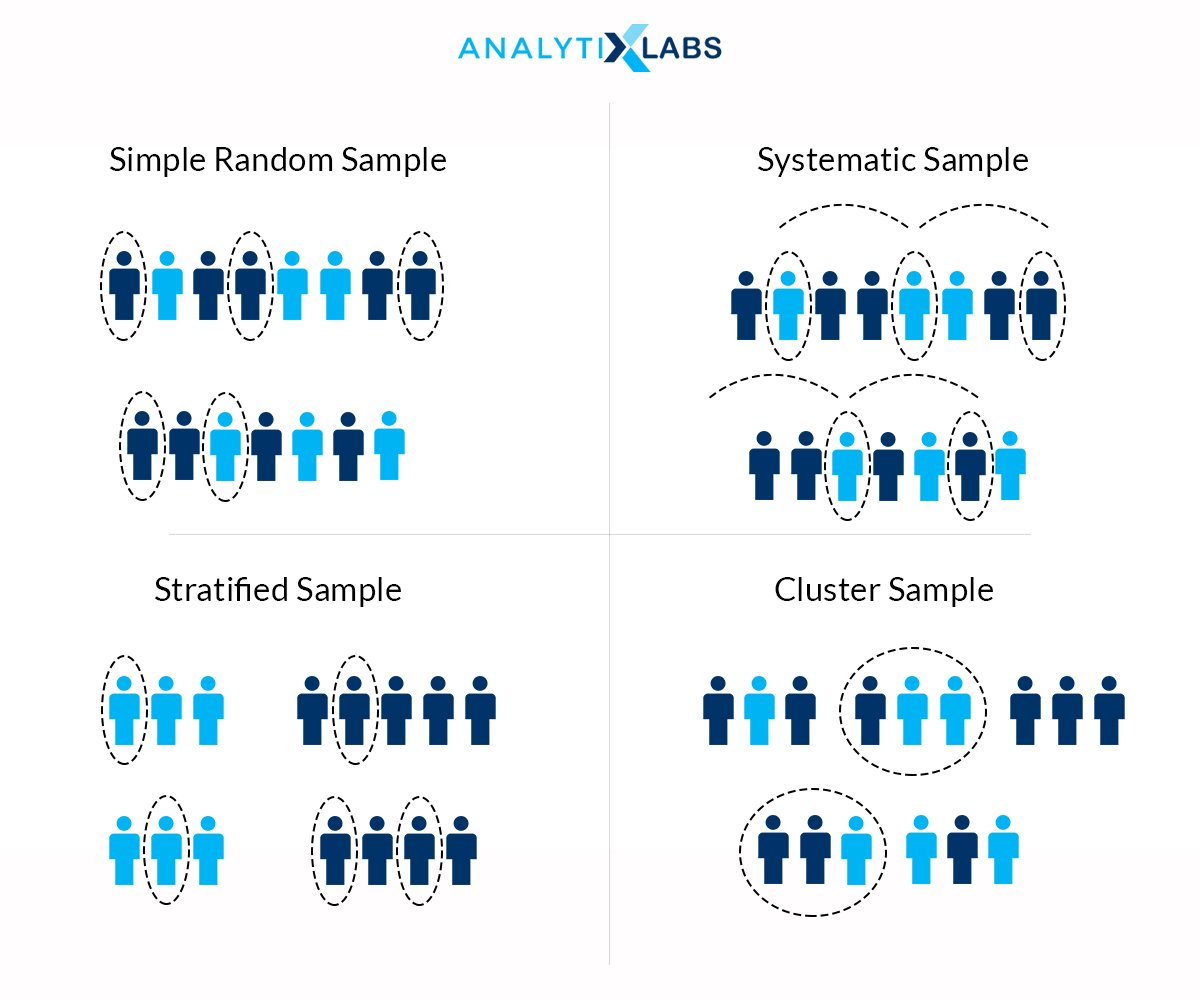
Sample
In simplest terms, a sample is nothing but a subset of the population (that ideally represents the population). The samples can be of various types such as
- Random Sample: Samples generated by randomly picking objects from the population and here random means without any bias or preconceived conditions. Here every object (or whatever the subject is in the population) gets an equal opportunity to be selected as a part of the sample.
- Stratified Sample: Here the samples are created by considering the underlying groups that could be found in the population. For example, if we are collecting a sample of cars on roads and if we have 40% hatchback and 60% sedans then while creating the sample, we will follow the same stratification.
- **Convenience Sampling: **Among the most widely used method of creating a sample, under this methodology, samples are not created by chasing after the subjects. A typical example of this would be online surveys or samples created through feedback forms etc. where the subjects at their own will provide the information.
- Clustered Sample: This form of a sample creation is most commonly conducted in collecting data for Exit polls, TRP calculation, advertisement placement, etc. Here the geographical area is divided where from each geographical entity a stratified or random sample is created.
One must keep in mind that no method is intrinsically better or worse than the other and are just different ways of creating a sample that suits different requirements.
The next logical question could be to question the very need of creating a sample in the first place. Why do we need to create a sample when we have the population and this has few obvious answers.
- Firstly, there can be a situation where capturing the population information is nearly impossible. For example, to know the age of each individual human being on earth. Finding the average of 7 billion numbers may not be an impossible technological task but to obtain such information is extremely tough. Here the population is highly dispersed which makes it difficult for us to obtain the complete data.
- The other reason can be when we have the population information i.e. a bank having a large number of branches throughout the world with each having hundreds of accounts which in turn makes numerous transactions. While such data may be available in the bank’s server, doing any operation on such a population data can be challenging because of its sheer velocity and volume.
#uncategorized #data science
