Kyle Brown, IBM Fellow, CTO Cloud Architecture, IBM Cloud and Cognitive Software
The last year has not been kind to a book that I believe to be one of the classic, and most important works of computer science — the book Design Patterns: Elements of Reusable Object Oriented Design. This is unfortunate, because the preceding year had been the 25th anniversary of the book’s publication and it’s odd that a book that old can generate such vitriol. The twitterverse in particular has been pretty savage to the book — using words like “impenetrable” and in one memorable put-down “the Atlas Shrugged of Computer Science”.
In a sense, I’m not surprised by this. Even when the book came out, it seemed it had as many detractors as it had supporters. What’s more, even when it was being written, there was a small but impassioned contingent of reviewers at the time that argued that the book needed to be completely rewritten before it was ever published. But every book has issues — and Design Patterns is not immune to the fact that any work is at best an imperfect reflection of the ideas of the authors.
However, what to my mind is the most difficult part to understand is that regardless of comments on the format, style, or even font choice of the work, I’ve never quite understood is how anyone could reject the ideas contained within it as being either trivial, useless, or banal. But then again, that’s where my experience as a programmer, and an author, differs from what I have found over the last twenty-five years to be the most common case.
So let’s start with the beginning. I first learned how to program in the same way many people of my generation did — we learned BASIC programming on a home computer. For me, it was a succession of them that I encountered at school, at friends houses, and eventually that I owned. During my high school years I learned to program on the Apple II in Integer and Applesoft BASIC, on the VIC-20, on the TI-99/4A, and on the Sinclair TX1000. Programming on the Sinclair, with only 4K and it’s bizarre shift-key combinations to create BASIC keywords was very different experience from programming on the relatively spacious 48K that the Apple II possessed and it’s wonderfully tactile keyboard that required you to fully type out all of your commands. As a result, I did a lot more low-level development with PEEK and POKE on the Sinclair than I did on the Apple, where the wonderful floating-point capabilities of Applesoft BASIC gave me free reign for my imagination. So nearly from the beginning, I learned that your available environment and language formed the way you thought about a problem.
Besides that, the way I learned to program was pretty typical for the time — I learned by writing programs. Now, there would be some programs that you could read — particularly those published in magazines where you had to type them in to run them (no internet!) and in the few that were available freely and circulated on BBS, disk and tape (long before “open source” became a thing), but in general, you learned how to solve problems by solving problems.
When I went to University for my degree, I found that this was still the predominant paradigm for learning the trickier bits of programming and of computer science. For example, when I took a class on operating systems, we would read about a concept, like a semaphore, or a file system, and then be expected to be able to implement the concept. There might be a few simple examples in the text to help get you over the hump as to how the implementation would work, but more often than not these were in a type of pseudocode that you would have to mentally translate into C or C++.
When I graduated from University and went to work as a C++ and C programmer, nothing much changed from the way I had learned things in college. Every programming problem began with searching out the documentation of the relevant libraries, then sitting down and plotting out how to write the solution from scratch. That was just the way I thought development should be, and always would be.
But then, in the winter of 1989, I had an unusual opportunity come my way that changed the way I thought about programming by changing the way I thought about how to solve problems. That opportunity was when I was introduced to Smalltalk (particularly the Smalltalk/V PM version from Digitalk). Writing programs in Smalltalk is such a departure from traditional ways of developing that it took me a long time to fully wrap my head around it. I’ve found that people that try to learn it end up in one of two extremes — either it becomes their all-time favorite development language and environment, or they hate it with a passion bordering on mania.
In order to understand why this is true, you need to understand some things that were, at the time completely radical about Smalltalk, and that even to this day, have not fully been replicated in any other development language or environment.
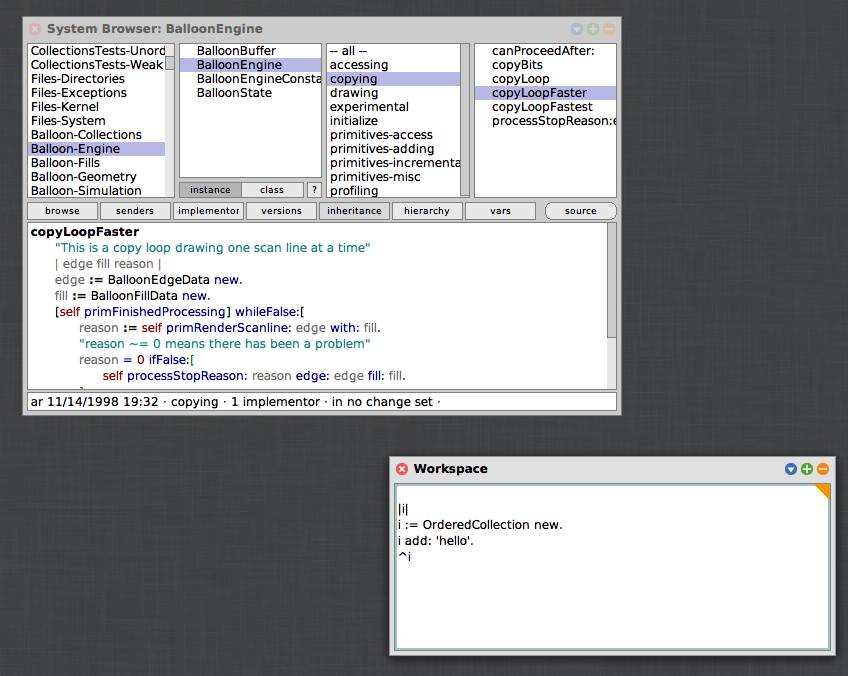
1. Smalltalk does not have files where you put your source code. Now, in a sense that’s a lie, because there IS a single file that contains your source code, but it’s not organized the way you think it might be. Instead of a single file for each module or class, all of the early Smalltalk implementations feature a single large, rolling log file, called the change log, that contains the new source code that you’ve added to the system. As you add a new method, or modify a method, it gets added on the end of the change file.
2. Smalltalk doesn’t have a file-based compilation system — instead, every change you make to any method or class definition in that changes file is instantly compiled by an incremental compiler and added into a single, large, in-memory image of the entire Smalltalk system.
3. Smalltalk was (and is) completely and totally Object-oriented. It was object-oriented in a way that Java, Python or C++ (or newer languages) cannot even match — in that even Integers are objects — and what’s more, you can extend the behavior of an Integer by adding new methods to it!
4. Smalltalk had this great concept called Workspaces that allowed you to highlight and run little snippets of code of any length — it would just compile and run them instantly. People would also mix and match documentation and code snippets within a Workspace — this is the basic idea behind Jupyter notebooks today. This was awesome for just trying something out to see what it did — part of a process of learning by exploration.
#smalltalk #software-engineering #coding #software-development #design-patterns