One of the problems with training very deep neural network is that are vanishing and exploding gradients. (i.e When training a very deep neural network, sometimes derivatives becomes very very small or very very big and this makes training difficult).In this blog, we will go through the details of both vanishing and exploding gradient.
Vanishing Gradient Problem:

When the gradients of the loss function with respect to the parameters in the early layers of a network are very small, it learns slowly and since many gradients are very small, they don’t contribute much to learning and can lead to poor performance.
In neural networks, weights are randomly initialized in the input layer. Summation of input features multiplied by weights along with the bias is passed into hidden layers .It is multiplied with output weights and passed to activation function to output layers it gives the predicted output. Then, compute the cost function (i.e the difference between the actual output and predicted output).

In order to minimize this loss we propagate backwards towards the network and update the new weights.
In earlier days, mostly used activation function was sigmoid activation function.
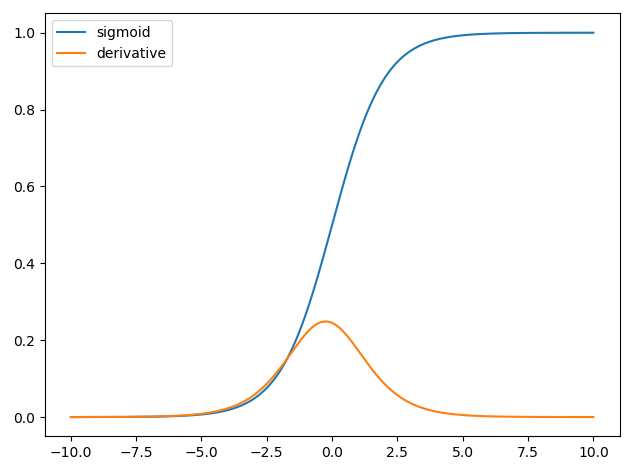
In sigmoid the values are converted between 0 and 1 and their derivatives lies between 0 and 0.25.The formula for weight updation is,

The learning rate must be very small so that the models learn gradually and finally converge to global minima.
As the number of layers in a neural network increases, the derivative keeps on decreasing. Hence, addition of more layers would lead to almost 0 derivative and
#analytics-vidhya #towards-data-science #data analytic