Usually in any K-means clustering problem, the first problem that we face is to decide the number of clusters(or classes) based on the data. This problem can be resolved by 3 different metrics(or methods) that we use to decide the optimal ‘k’ cluster values. They are:
- Elbow Curve Method
- Silhouette Score
- Davies Bouldin Index
Let us take a sample dataset and implement the above mentioned methods to understand their working.
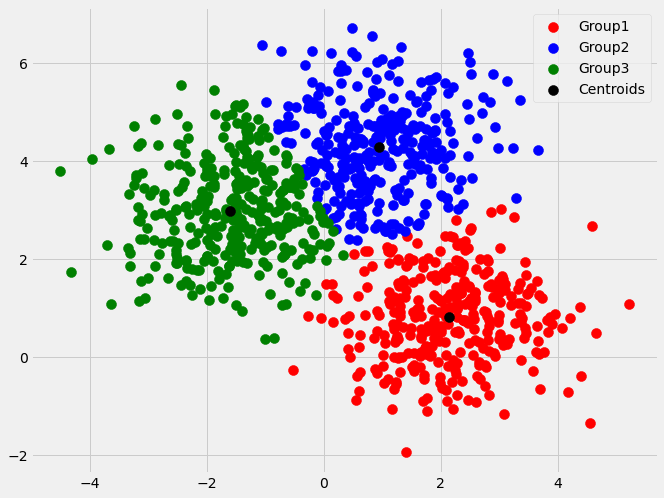
We will use the make blobs dataset from sklearn.datasets library for illustrating the above methods
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=1000, n_features=2,random_state=0)
Now let’s look at what these methods area and that after implementing those three methods on the created dataset what are the results.
#clustering #machine-learning #ai #data-science #k-means
1.50 GEEK