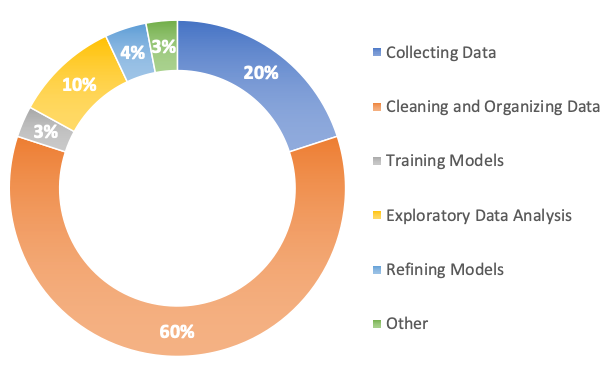
Forbes’s survey found that the least enjoyable part of a data scientist’s job encompasses 80% of their time. 20% is spent collecting data and another 60% is spent cleaning and organizing of data sets. Personally, I disagree with the notion that 80% is the least enjoyable part of our jobs. I often see the task of data cleansing as an open-ended problem. Typically, each data set can be processed in hundreds of different ways depending on the problem at hand but we can very rarely apply the same set of analyses and transformations from one dataset to another. I find that building different processing pipelines and examining how their differences affect model performance is an enjoyable part of my job.
With that said, I want to take the time and walk you through the code and the thought process of preparing a dataset for analysis which in this case will be a regression (ie. multiple regression).
#cardinalities #regression-analysis #data-processing #feature-engine #python