Most of us always tend to find similarities between things or persons. For instance, we find similarities between actors, players, etc. But if an algorithm does it for us we would not need to do things by ourselves. One of the ML Algorithm can help us out in this.
Kmeans clustering is a simple and commonly used unsupervised Learning algorithm in Machine Learning. In this article, I will try to tackle the process of assessing similarity using the Kmeans clustering algorithm.
**Clustering **is one of the common data analysis techniques used to find the structure of data and track results out of it. It can be defined as classifying the data into groups and finding subgroups within it was the data points are similar. This method is considered as unsupervised learning as here we don’t have labels to compare the output we get and evaluate the performance. Clustering groups the data points and investigates the structure. Kmeans is considered as one of the most used clustering algorithms.
Kmeans algorithm is an iterative algorithm that partitions the data set using the clustering technique into k clusters with a centroid for each cluster and finds the distance between the data points and centroids using distance metrics such as euclidean distance, hamming distance, etc., and iteratively does the clustering process.
This finally groups similar data points into clusters based on the features of the data. I have used the NBA player’s stats to use the means and find similarities between the players based on various features.
We are using player data from the NBA Regular season and are combining two data-sets from the website, Basketball-reference. The first data-set from Basketball-reference comprises of traditional NBA statistics (points, rebounds, etc).
Sample data from first data set
The second one consist of advanced stats data of the NBA players.
sample data from advanced stats data
Data Cleaning and Pre-processing:
Initially remove the null values by dropping the null rows or columns .else a better way is to fill the null data with some aggregate value. For instance fill null values in the 2p%, 3p% columns in first data set to 0 as it cannot be aggregated. After removing the null values merge the two datasets and filter out the essential columns out of it to a data frame for our algorithm to process. Filtering out the essential features is an important part of data processing which could give great effects on the results of our algorithm.
The result data set of all the processing I used is,
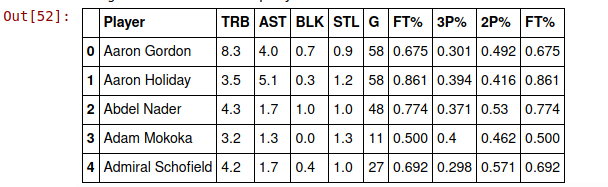
sample data from the merged data set
Drop out the player column before passing into the algorithm as it will be accessed through the index later on.
#machine-learning #unsupervised-learning #k-means-clustering #deep learning