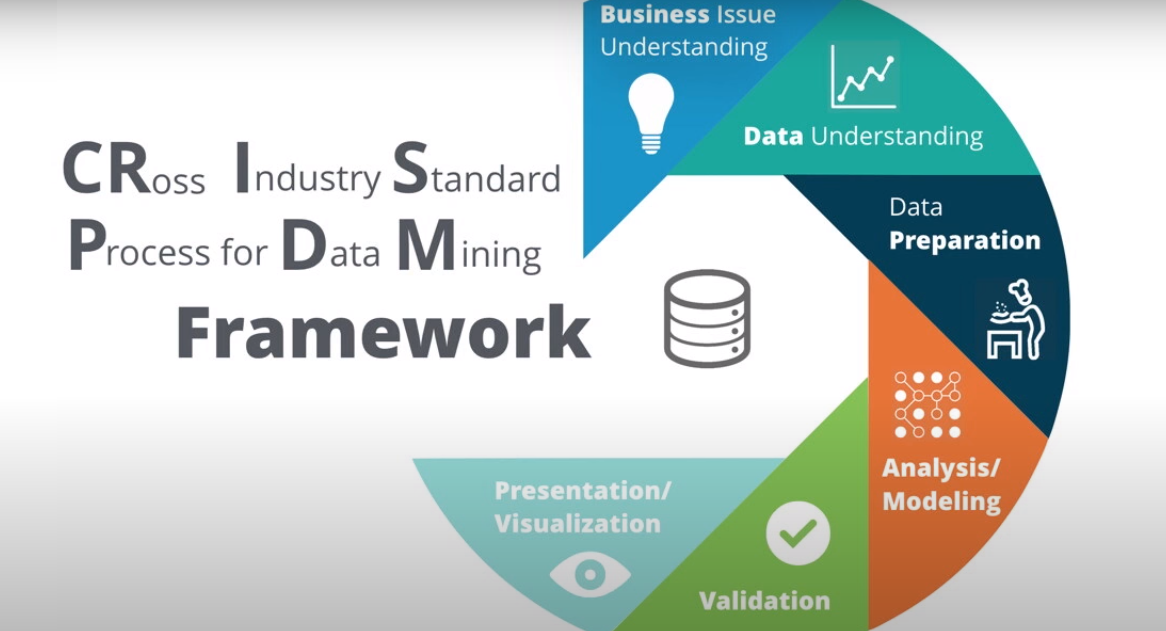
If you’re interested in the exciting world of data science, but don’t know where to start, CRISP-DM Framework is here to help.
Let’s see one by one how these steps play a vital role in learning data science in flow~
Step 1 Business understanding:
The first stage of the framework is to develop a business understanding. For this, you have to carry out two steps:
- Determine the business objective -Determining the business objective is of high importance. Until the business objectives have been finalized, the data cannot be collected or worked upon.
- **Identify the goal of the data analysis- **Determine the goals of data analysis, because without goal project is of no use.
Same way learners have to select the Business domain in which they are planning to become a data scientist and then try to become SME of that particular domain. Without business domain knowledge they unable to meet the Step1 requirements and eventually would face difficulties in other steps. Once we know the business we can easily apply our data science skills to drive more value out of that business data.
_Some trending domains: _Healthcare, Fintech, Real Estate, E-commerce, EduTech etc.
Step 2 Data Understanding
This stage comprises of two key steps to understand the available data and identify new relevant data in order to solve the business problem.
- Describe data- Once you have identified the data set, you need to describe its contents and explore insights to better understand the data and its business implications. To describe the data, we can create a data dictionary that lists down the types of variables (e.g. sectors, company names, etc.), the number of records, and the types of analysis.
For describing data learner needs to know one programming language(R ,Python or sas) and excel so that they can easily do first-level analysis and then can create data dictionary.
- Explore data- To explore data, you can plot simple graphs on Excel/R/Python, e.g. to understand the trend in data or to get a graphical representation of data for better understanding to get useful insights.
_For exploring data learners needs to know __EDA -Exploratory data analysis _which could be done with the help of statistics knowledge.
Step 3 Data Preparation
“Give me six hours to chop down a tree and I will spend the first four sharpening the axe.”
Data preparation is the most important and time-consuming step in this data needs to be prepared by doing some data preprocessing like data transformation, aggregation etc. We can create new attributes using our existing here new attributes are called derived attributes, eg. deriving age from dob etc.
The data preparation has various rigorous steps including the following:
- Filling missing data
- Removing data
- Transforming data
#data-scientist #data-science #data #data-analysis #statistics #data analysis