Introduction
Over time, we rely more and more heavily on online platforms and applications such as Netflix, Amazon, Spotify etc. we are finding ourselves having to constantly choose from a wide range of options.
One may think that having many options is a good thing, as opposed to having very few, but an excess of options can lead to what is known as a “decision paralysis”. As Barry Schwartz writes in The Paradox of Choice:
“A large array of options may discourage consumers because it forces an increase in the effort that goes into making a decision. So consumers decide not to decide, and don’t buy the product. Or if they do, the effort that the decision requires detracts from the enjoyment derived from the results.”
Also resulting in another, more subtle, negative effect:
“A large array of options may diminish the attractiveness of what people actually choose, the reason being that thinking about the attractions of some of the unchosen options detracts from the pleasure derived from the chosen one.”
An obvious consequence of this, is that we end up not making any effort in scrutinising among multiple options unless it is made easier for us; in other words, unless these are filtered according to our preferences.
This is why recommender systems have become a crucial component in platforms as the aforementioned, in which users have a myriad range of options available. Their success will heavily depend on their ability to narrow down the set of options available, making it easier for us to make a choice.
A major drive in the field is Netflix, which is continuously advancing the state-of-the-art through research and by having sponsored the Netflix Prize between 2006 to 2009, which hugely energised research in the field.
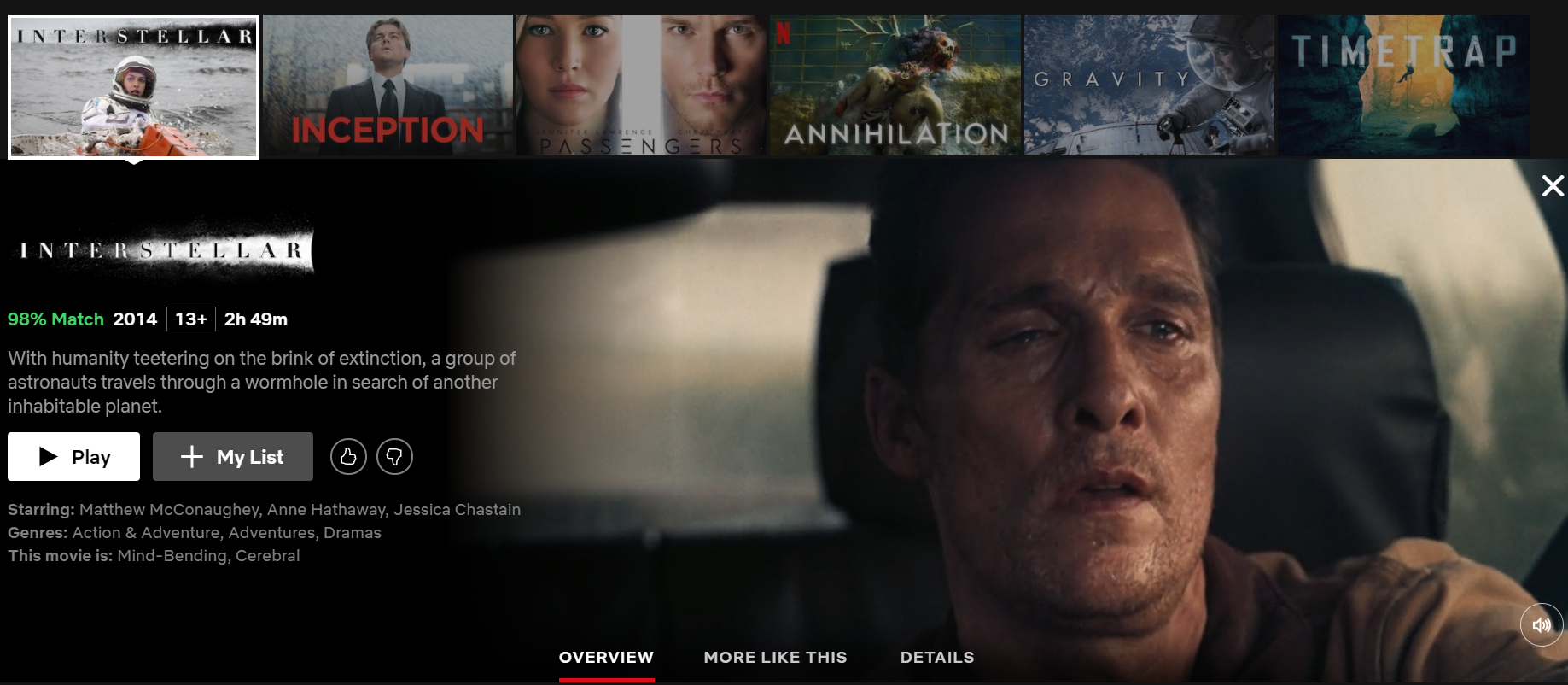
In addition, the Netflix’s recommender has a huge presence in the platform. When we search for a movie, we immediately get a selection of similar movies which we are likely to enjoy too:
Outline
This post starts by exposing the different paradigms in recommender systems, and goes through a hands on approach to a content based recommender. I’ll be using the well known MovieLens dataset, and show how we could recommend new movies based on their features.
This is the first in a series of two posts (perhaps more) on recommender systems, the upcoming one will be on Collaborative filtering.
Find a jupyter notebook version of this post with all the code here.
#recommendations #python #data-science #machine-learning #recommendation-system
