In these series of articles, we are exploring various other approaches of detecting faces rather than the common ones. In the previous article (Part1 and Part 2), we discussed about RetinaFace and SSH.
In this part we’ll discuss about _PCN: Progressi_ve Calibration Networks.

PCN: Progressive Calibration Networks
Rotation invariant face detection i.e detecting rotated faces is widely required in unconstrained applications but still it remains a challenging task due to large variation of face appearances.
For addressing this problem, Progressive Calibration Networks(PCN) performs rotation-invariant face detection in a coarse-to-fine manner. PCN consists of three stages which detects faces and also calibrates RIP(Rotation in Plane) orientation of each face candidate to upright progressively.
PCN first calibrates those face candidates which as facing down to up, halving the range of RIP angles from [-180, 180] to [-90, 90]. Then the rotated faces further calibrated to upright range [-45, 45], halving RIP again. And then PCN makes the final decision for each face candidate and predicts precise RIP angle. It is discussed in detail below.
Architecture
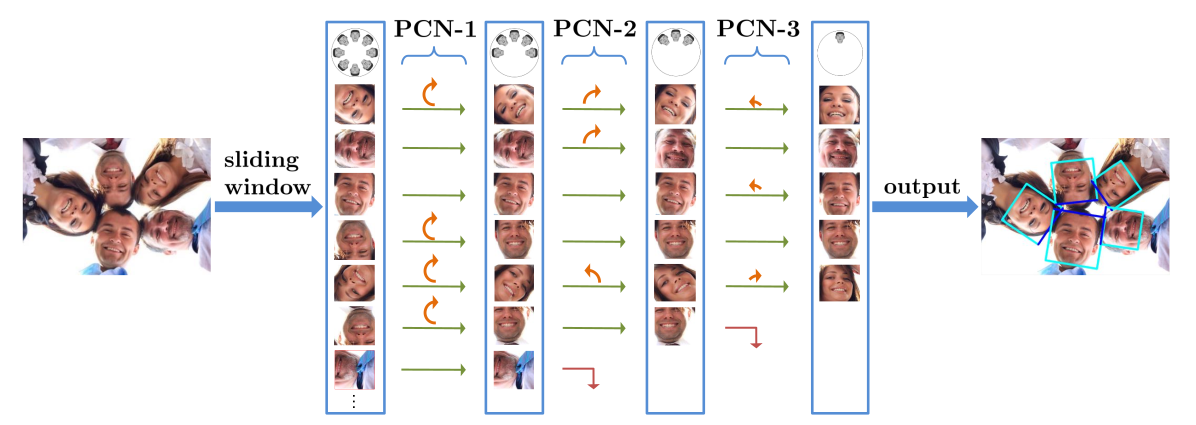
Proposed Framework
On an image all face candidates are obtained according to sliding window and image pyramid principle and each candidate window goes through the detector stage by stage [Here, 3 stages]. In each stage of PCN, the detector rejects faces with low confidence score, regresses bounding boxes of remaining face candidates and calibrates RIP. After each stage NMS is used to merge highly overlapping candidates.
PCN-1 1st Stage
For each input window x, PCN-1 has three objectives i.e. face/no face classification, bounding box regression and calibration.
The first objective which aims for classifying face and non-faces is achived by Softmax loss :
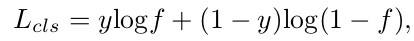
where y equals to 1 if x if face, otherwise 0 and f is classification score.
The second objective attempts to regress the bounding boxes as :
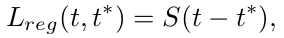
where t and t* represents the predicted and ground truth regression results and S is smooth L1 loss. The bounding box values consists of:
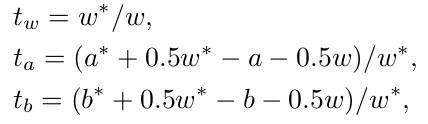
where a, b and w denotes bounding box top-left coordinate and width. Variable without () are predicted values and with () are ground truth values.
#face-recognition #artificial-intelligence #face-detection-app #computer-vision #deep-learning #deep learning
