Elasticsearch is a feature-rich, open-source search-engine built on top of **Apache Lucene, **one of the most important full-text search engines on the market.Elasticsearch is best known for the expansive and versatile REST APIexperience it provides, including efficient wrappers for full-text search, sorting and aggregation tasks, making it a lot easier to implement such capabilities in existing backends without the need for complex re-engineering.Ever since its introduction in 2010, Elasticsearch gained a lot of traction in the software engineering domain and by 2016 it became the most popular enterprise search-engine software stack according to DBMS knowledge base DB-engines, surpassing the industry-standard Apache Solr (which is also built on top of Lucene).
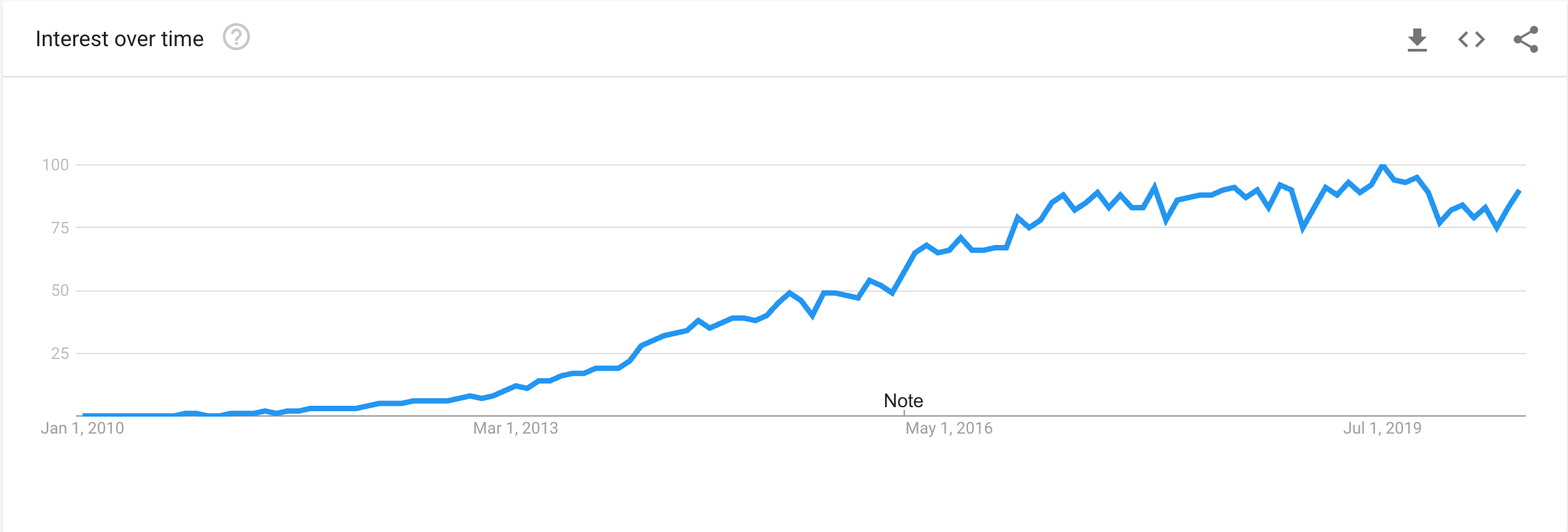
Google Trends data for Elasticsearch since its release in 2010
One of the things that makes Elasticsearch so popular is the ecosystem it generated. Engineers across the world developed open-source Elasticsearch integrations and extensions, and many of these projects were absorbed by Elastic (the company behind the Elasticsearch project) as part of their stack.Some of the projects were Logstash (data processing pipeline, commonly used for parsing text-based files) and Kibana (visualization layer built on top of Elasticsearch), leading towards the now widely adopted ELK (Elasticsearch, Logstash, Kibana) stack.The ELK stack quickly gained notoriety due to its impressive set of possible applications across both emerging and consolidated tech domains, such as DevOps, Site-Reliability Engineering, and, most recently, _Data Analytics._But what about Data Science?Chances are that if you’re a data scientist reading this article and have Elasticsearch as part of your employer’s tech stack, you might have had some problems trying to use all the features Elasticsearch provides for data analysis and even for simple machine learning tasks.Data scientists are generally not used to NoSQL database engines for common tasks or even relying on complex REST APIs for analysis. Dealing with large amounts of data using Elasticsearch’s low-level python clients, for example, is also not that intuitive and has somewhat of a steep learning curve for someone coming from a field different from SWE.Although Elastic made significant efforts in enhancing the ELK stack for Analytics and Data Science use cases, it still lacked an easy interface with the existing Data Science ecosystem (pandas, numpy, scikit-learn, PyTorch,and other popular libraries).In 2017, Elastic took it first step towards the data science field and, as an answer to the growing popularity of Machine Learning and predictive technologies in the software industry, released their first ML-capable X-pack (extension pack) for the ELK stack, adding Anomaly Detection and other unsupervised ML tasks to its features. Not long after that, Regression and Classification models (1) were also added to the set of ML tasks available in the ELK stack.Last week another step towards Elasticsearch achieving widespread adoption in the data science industry, with the release of Eland, a brand new Python Elasticsearch client and toolkit with a powerful (and familiar) pandas-like API for analysis, ETL and Machine Learning.
#machine-learning #pandas #elasticsearch #python #data-science
