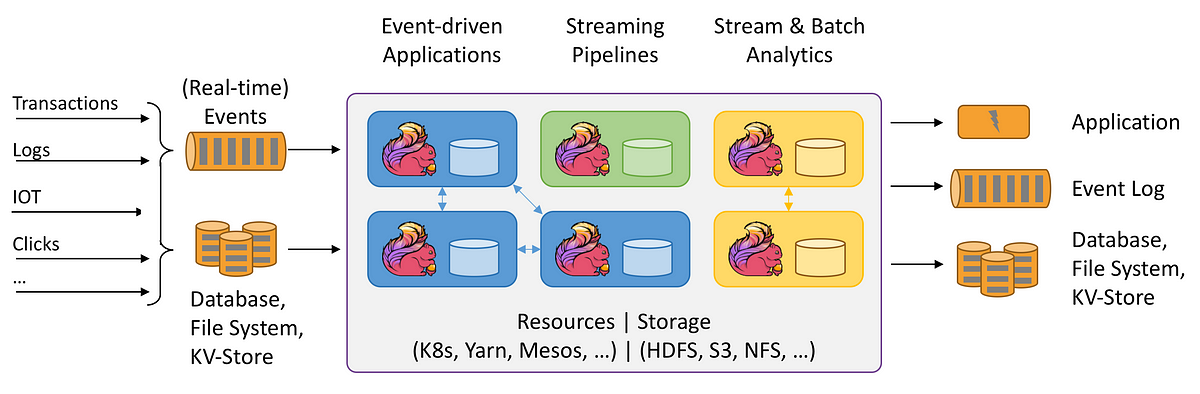
In many application domains, massive streaming data is generated from different sources, for example, user activities on the web, measurements from the Internet of Things (IoT) devices, transactions from financial services, and location-tracking feeds. These data streams (unbounded) that traditionally used to be stored as datasets (bounded), and processed later by batch processing jobs. Although this is not an efficient way in some scenarios due to the time value of the data, where the real-time processing is desirable by businesses to enable them to get insights from data and proactively respond to changes as close as the data is being produced (in motion).
Toward that, the applications have to be updated to be more stream-based using real-time stream processors. That is where Apache Flink comes in; Flink is an open-source framework for stateful, large-scale, distributed, and fault-tolerant stream processing.
This blog post presents an overview of Apache Flink and its key features for streaming applications. It focuses on Flink’s DataStream API and explores some of the underlying architectural design concepts.
Most of the details of this post are based on my hands-on experience in Flink during my involvement in the datAcron EU research project as summarised in this paper.
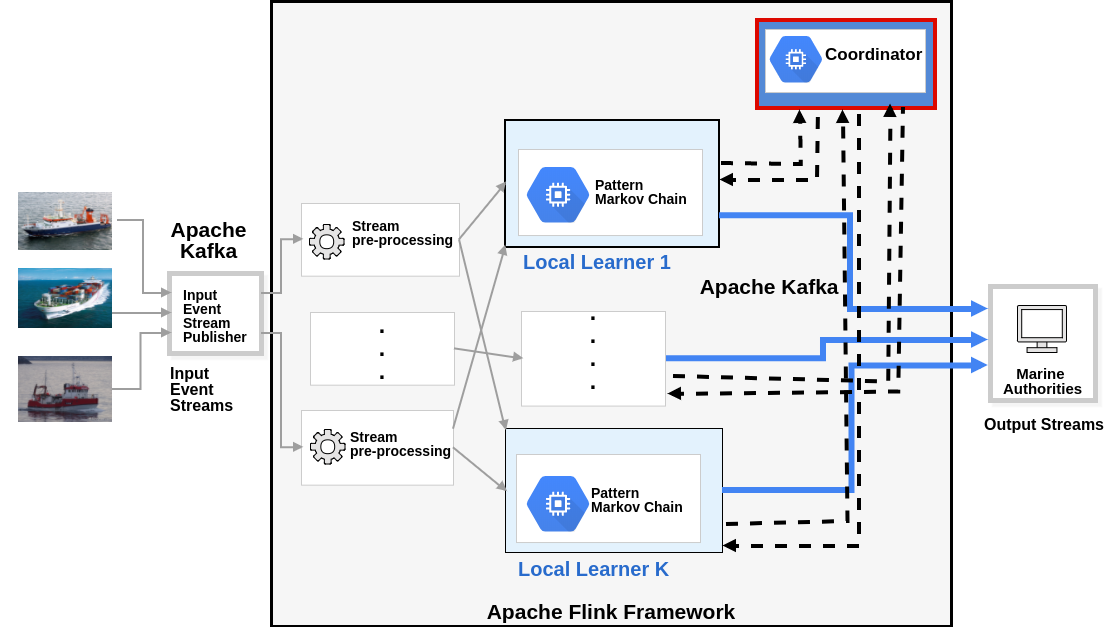
Distributed Online Learning System Archircture using Apache Flink. Photo by the author | Photo from A Distributed Online Learning Approach for Pattern Prediction over Movement Event Streams.
Apache Flink is gaining more popularity and it is being used in production to build large-scale data analytics and processing components over massive streaming data, where it powers some of the world’s most demanding stream processing applications, for example, it is a crucial component of Alibaba’s search engine.
#apache-flink #event-driven-architecture #big-data #stream-processing #apache