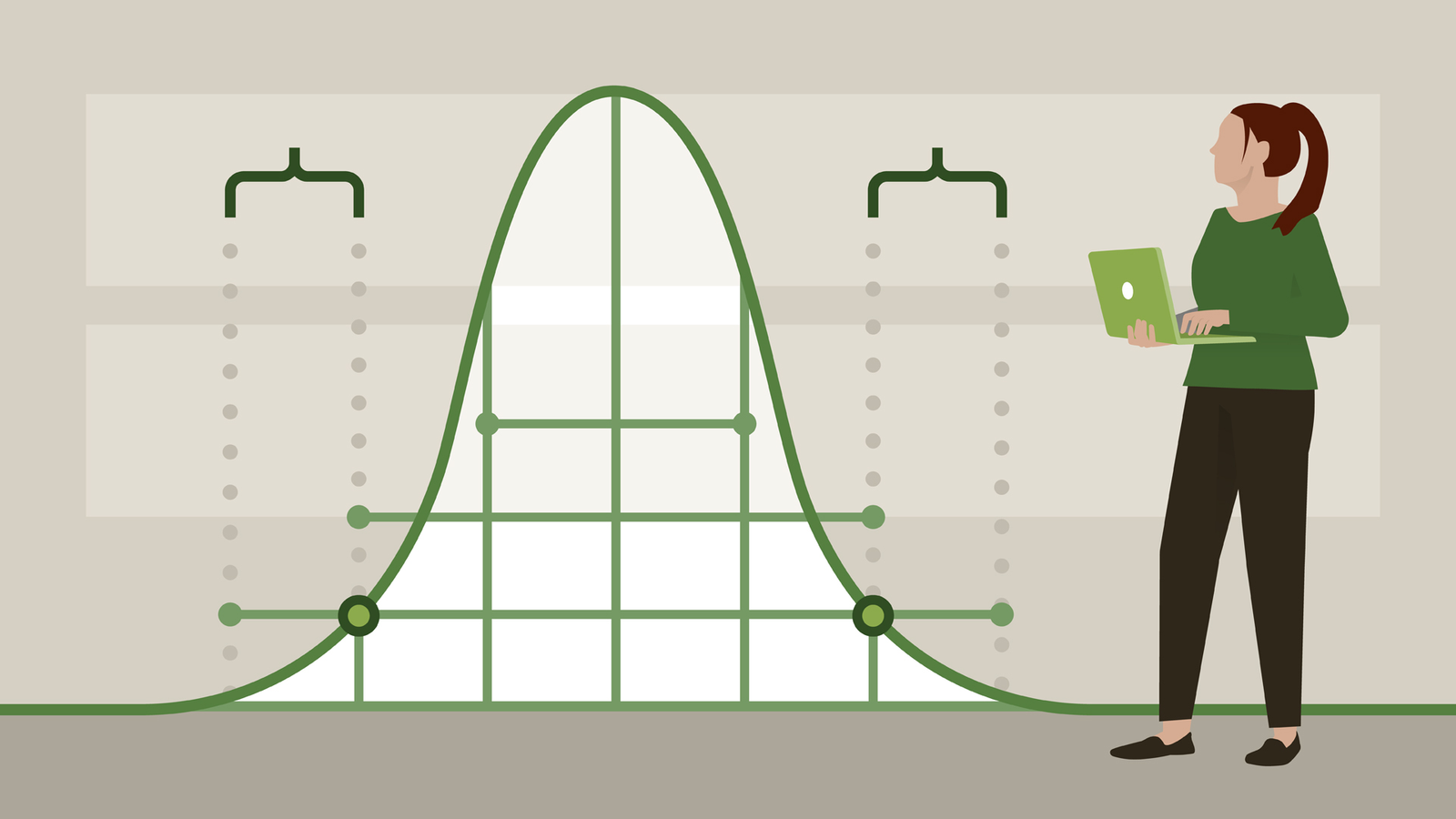
Hypothesis testing is about to allow statisticians and data scientists to make decisions for the real-world based on the results of their statistical analysis.
That’s made using the probability of results errors, to explain how to calculate if a statistic represents the real-world data, we need to introduce some probability terminology.
Introduction
Hypothesis testing is about to analyze if the results of a change in any situation work better than using the current methodology. So we can check if the modifications that our model implies upgraded the previous version.
To check it, we set two hypotheses, the Null HypothesiS says that our model application doesn’t upgrade the situation, and the Alternative hypothesis says that our model is better than the previous. Both hypotheses should be mutually exclusive, in other words, the intersection of probabilities should be null.
If we fail to reject the null hypothesis, our model results will not upgrade the actual model, because differences in the results means are not statistically significant.
The process of testing this significance is done by p-values, choosing a probability when results will be considered to reject the Null Hypothesis. Historically the most used p-values are 0.05, but in modern eras, it’s getting to 0.01 or 0.001.
#deep-learning #data-sicence #mathematics #machine-learning #statistics