Altering the physical execution plan at runtime.
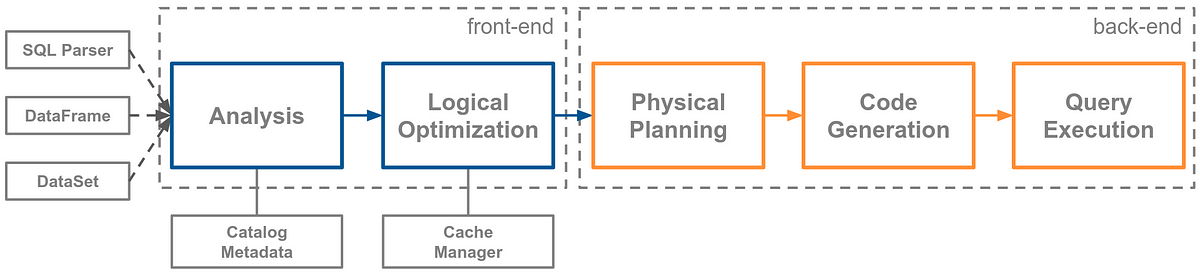
Level of parallelism and selection of the right join strategy have shown to be the key factors when it comes to complex query performance in large clusters.
Even though Spark 2.x already implemented a few parameters to somehow tweak its related behaviour, having to manually tune them was not practical in many production scenarios. Besides, a static configuration may not be the right one for all stages of a job, as usually stages located closer to the final output…
#spark-3 #distributed-systems #spark-catalyst #spark-sql #apache-spark
1.75 GEEK