A Small Introduction to Kafka!
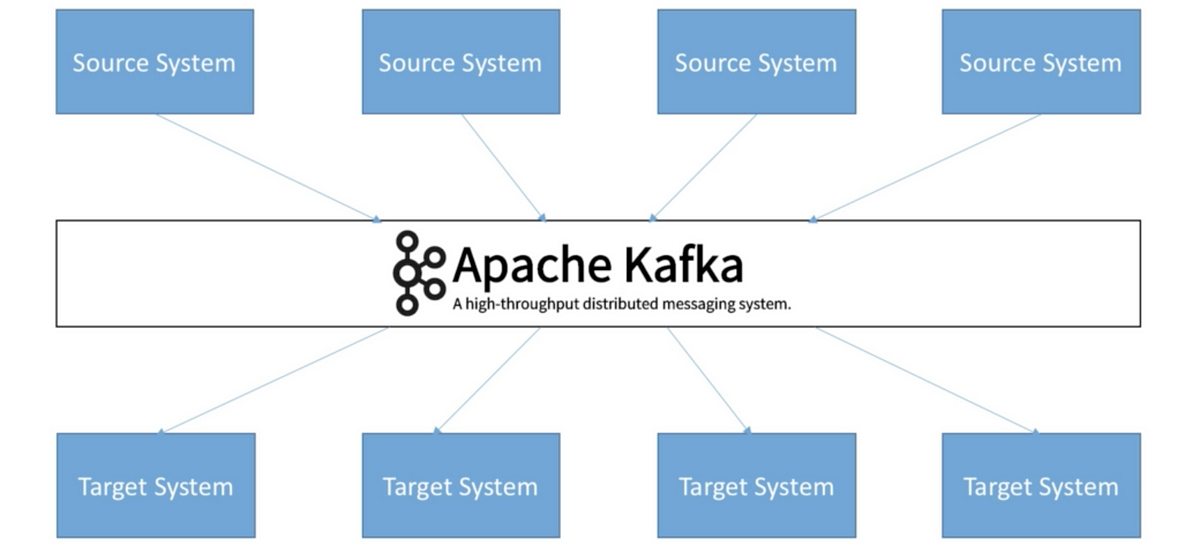
So before we learn about Kafka, let’s learn how companies start. At first, it’s super simple. You get a source system, and you have a target system and then you need to exchange data. That looks quite simple, right? And then, what happens is, that after a while you have many source systems, and many target systems and they all have to exchange data with one another, and things become really complicated. So the problem is that with a previous architecture
- Each integration comes with difficulties around
Protocol — how the data is transported (TCP, HTTP, REST, FTP)
Data format — how the data is parsed (Binary, CSV, JSON, Avro)
Data schema & evolution — how the data is shaped and may change
- Additionally, each time you integrate a source system with the target system, there will be an increased load from the connections
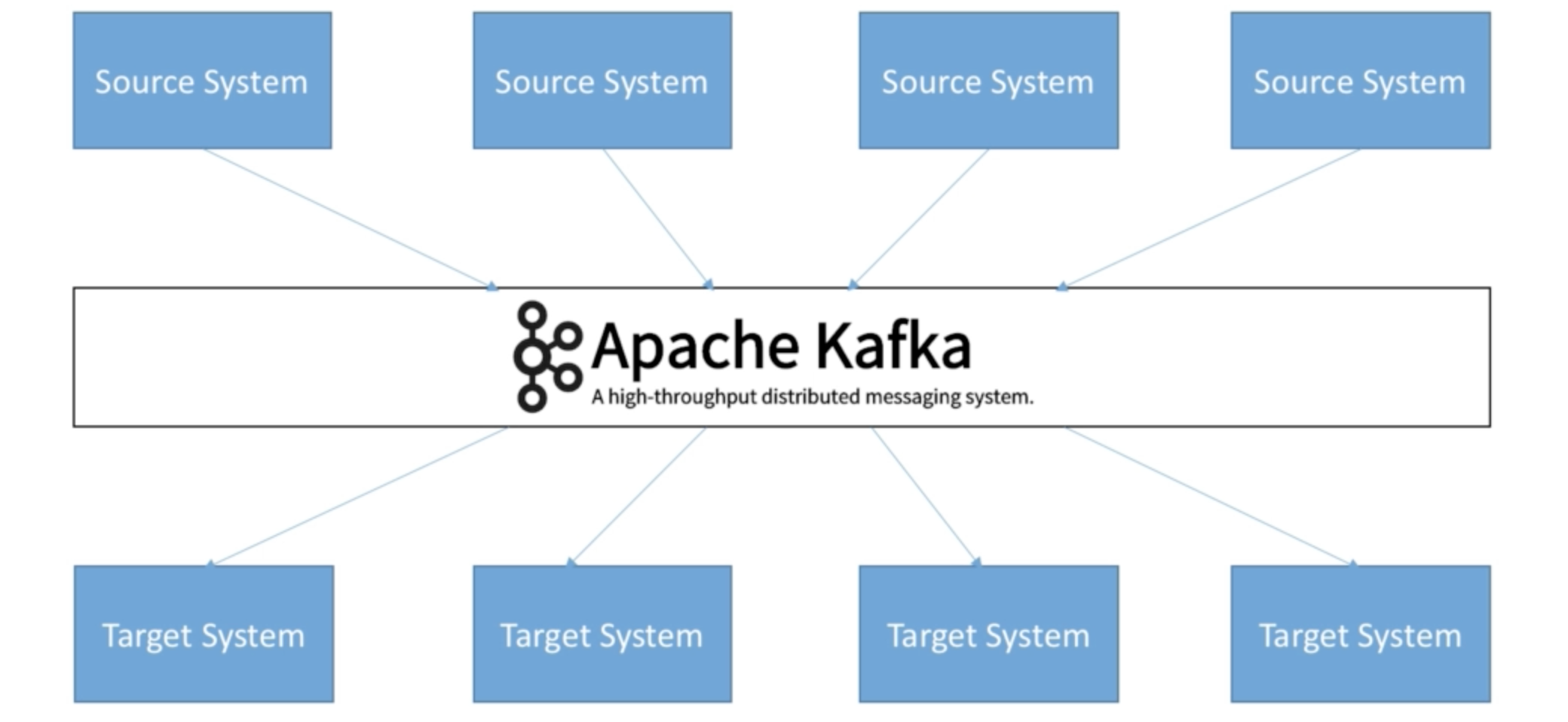
So how do we solve this? Well, this is where Apache Kafka comes in. So Apache Kafka, allows you to decouple your data streams and your systems. So now your source systems will have their data end up in Apache Kafka. While your target systems will source their data straight from Apache Kafka and so this decoupling is what is so good about Apache Kafka, and what it enables is really really nice. So for example, what do we have in Kafka? Well, you can have any data stream. For example, it can be website events, pricing data, financial transactions, user interactions, and many more.
#kafka-streams #devops #kafka #kafka-connect #best-practices