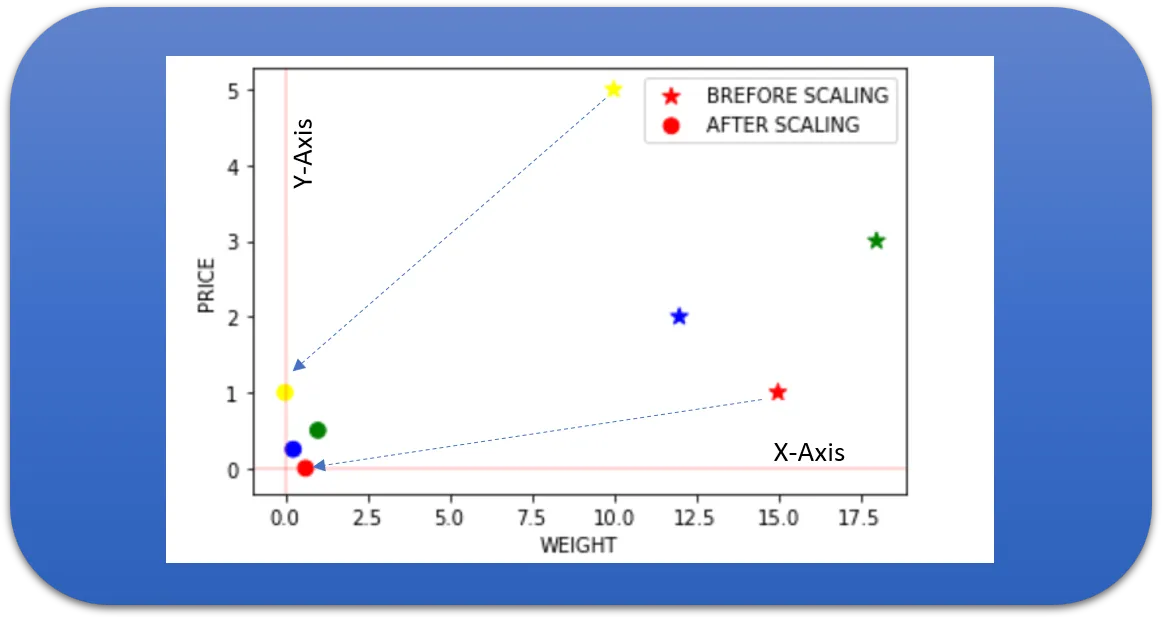
Feature Scaling is a Data Preprocessing step used to normalize the features in the dataset to make sure that all the features lie in a similar range.
Why Feature Scaling?
Most of the real-life datasets that you will be dealing with will have many features ranging from a wide range of values.
Like if you are working with a machine learning problem in which you need to predict the price of a house, you will be provided with many features like no.of. bedrooms, square feet area of the house, etc…

As you can guess, the no. of bedrooms will vary between 1 and 5, but the square feet area will range from 500–2000. This is a huge difference in the range of both features.
Many machine learning algorithms that are using euclidean distance as a metric to calculate the similarities will fail to give a reasonable recognition to the smaller feature, in this case, the number of bedrooms, which in the real case can turn out to be an actually important metric.
Some of the machine learning algorithm, that needs feature scaling for better prediction are Linear Regression, Logistic Regression, KNN, KMeans, Principal Component Analysis, etc.
There are several ways to scale your dataset. I will be discussing on 5 of the most commonly used feature scaling techniques.
- Absolute Maximum Scaling
- Min-Max Scaling
- Normalization
- Standardization
- Robust Scaling
Originally Posted on my Website — Let’s Discuss Stuff
#normalization #feature-scaling #machine-learning #statistics #python