This is a competition in Kaggle by Google Quest which aims at classifying questions and answers collected from a number of websites into various labels. Machines are good at answering questions which are objective in nature but when it comes to subjective questions humans are better at understanding the context. In this competition, the challenge is to build a model which understands different subjective aspects of question-answering.
Problem Statement
The question-answer pairs have been gathered from nearly 70 different websites, in a “common-sense” fashion. The data includes questions and answers from various _StackExchange _properties. The task is to predict values of 30 labels for each question-answer pair. There are 6079 training data points each having a question title, question body and answer along with some other meta information. The test data contains 476 data points for which we need to predict the score for each of the** 30 labels**.

Questions in this dataset are in many forms — some have multi-sentence elaborations, others are simple curiosity or a fully developed problem. They have multiple intents, or seek advice and opinions. Some are helpful and others are interesting. Some are simply right or wrong.
Rating has been provided on each of these factors for each question-answer pair. To address the subjective nature of the problem, instead of predicting binary labels it is required to get a score in the range of 0 to 1 for each of these labels.
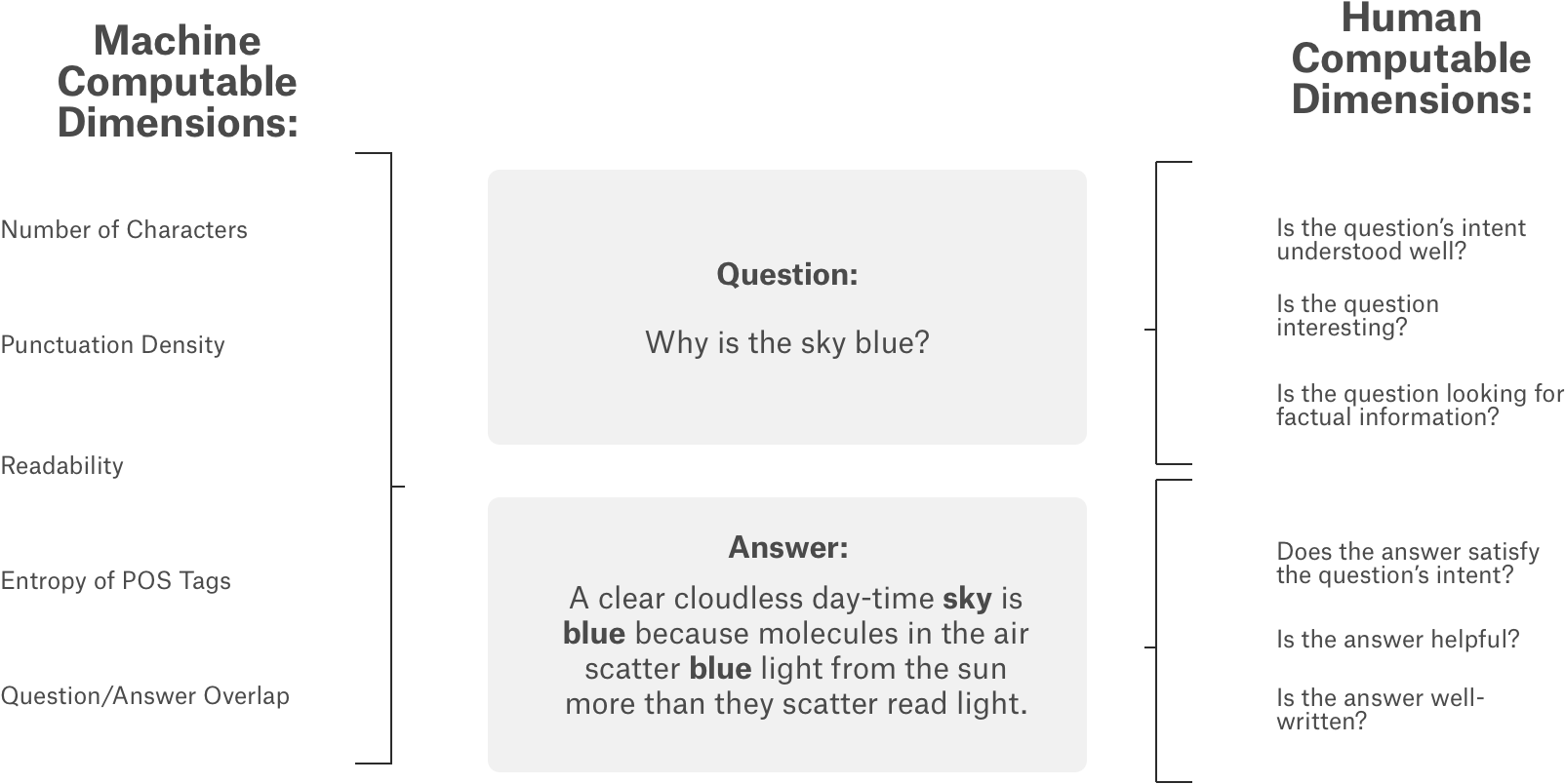
Mapping to Machine Learning problem
We are provided with a bunch of text data and some other metadata along with 30 target variables. This can be treated as a regression problem which will use encoded features as inputs and calculate the corresponding ratings for each of the target variables.
The evaluation metrics for this competition is Spearman’s Rank Correlation coefficient (rho). The Spearman’s rank correlation is computed for each target column, and the mean of these values is calculated to get the final score.
The Spearman correlation coefficient is defined as the Pearson correlation coefficient between the rank variables. In simpler terms, instead of calculating the correlation between the actual values we find the correlation between the ranks of variables. You can refer to this article if you wish to understand how Spearman’s Rank Correlation coefficient is calculated.
The following snippet of code is an illustration of how to obtain Spearman’s Rank Correlation coefficient for multiple columns in Python.
#kaggle-competition #transfer-learning #deep-learning #nlp #keras #deep learning
