1. Introduction
Image Captioning is a challenging artificial intelligence problem which refers to the process of generating textual description from an image based on the image contents. For instance, look at the picture below:

A common answer would be “A woman playing a guitar”. We as humans can look at a picture and describe whatever it is in it, in an appropriate language. This is easy. Let me show you another one:
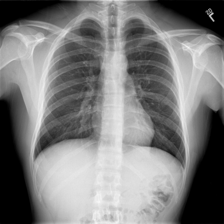
Well, how would you describe this one?
For all of us ‘non-radiologists’, a common answer would be _“a chest x-ray”. _Well, we are not wrong but a radiologist might have some different interpretations. They write textual reports to narrate the findings regarding each area of the body examined in the imaging study, specifically whether each area was found to be normal, abnormal or potentially abnormal. They can derive such valuable information and make medical reports from one such image.
For less-experienced radiologists and pathologists, especially those working in the rural areas where the quality of healthcare is relatively low, writing medical-imaging reports is demanding or on the other hand for experienced radiologists and pathologists, writing imaging reports can be tedious and time consuming.
So, to address all these matters, wouldn’t it be great if a computer can take a chest x-ray like the one above as input and output the findings as text just like how a radiologist would do?

Image by the Author | Are we asking a machine to be a doctor now?!!
But, can you indeed write such a computer program? Well, if the answer was ‘no’, you wouldn’t be reading this story.
2. Prerequisites
This work assumes some deep learning familiarity with topics like Neural Nets, CNNs, RNNs, Transfer Learning, Python programming and Keras library. The two below mentioned models will be used for our problem, which will be explained briefly later in this blog itself:
- Encoder-Decoder Model
- Attention-Mechanism
Decent knowledge about them will help you understand the models better.
3. Data
You can obtain the data needed for this problem from the below links:
- Images**_- _**Contains all the chest X-rays.
- Reports**_- _**Contains the corresponding reports for the above images.
The image dataset contains multiple chest x-rays of a single person. For instance: side-view of the x-ray, multiple frontal views etc. Just as a radiologist uses all these images to write the findings, the models will also use all these images together to generate the corresponding findings. There are 3955 reports present in the dataset, with each report having one or more images associated with it.
3.1. Extracting the Required Data From the XML files
The reports in the dataset are XML files where each file corresponds to an individual. The image IDs and the corresponding findings associated with that person is contained in these files. An example is shown below:


The left image shows the ‘findings’ in the file whereas the right image shows the given image IDs of the same file
The highlighted info are the things that you need to extract from these files. This can be done with the help of python’s XML library.
**NOTE: **The findings will be also referred to as reports. They will be used interchangeably in the rest of the blog.
Extracting Findings and Reports from the XML file
4. Obtaining Structured Data
After extracting the required data from the XML files, the data is converted into a structured format for easy understanding and accessibility. As mentioned before, there are multiple images associated with a single report. Therefore, our model also needs to see these images while generating reports. But some reports have only 1 image associated with it, while some have 2 and the maximum being 4.
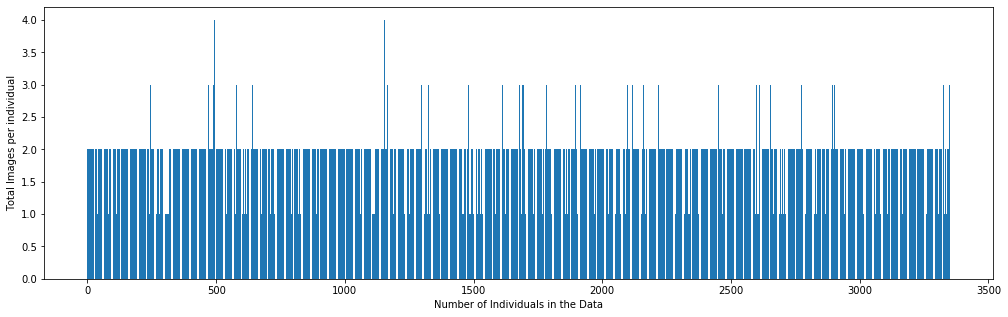
Image by the Author | Graph showing the number of Images associated per report
So the question arises, how many images should we feed into the model at a time to generate a report? To make the model-input consistent, pairs of images i.e two images were chosen at a time as input. If a report only had 1 image, the same image would be replicated as the second input.

A glance on how the structured data would look like
Now we have a proper and understandable structured data to work with. The images are saved by the names of their absolute address. This will be helpful while loading the data.
5. Prepare Text Data
After obtaining the findings from the XML file, they should be properly cleaned and prepared before we feed it into the model. Below image shows a few examples of how findings would look like before its cleaned.

Example Findings before they are cleaned
We will clean the text in the following ways:
- Convert all characters into lowercase.
- Perform basic decontractions i.e words like won’t, can’t and so on will be converted to will not, cannot and so on respectively.
- Remove punctuation from text. Note that full stop will not be removed because the findings contain multiple sentences, so we need the model to generate reports in a similar way by identifying sentences.
- Remove all numbers from the text.
- Remove all words with length less than or equal to 2. For example, ‘is’, ‘to’ etc are removed. These words don’t provide much information. But the word ‘no’ will not be removed since it adds value. Adding ‘no’ to a sentence changes its meaning entirely. So we have to be careful while performing these kind of cleaning steps. You need to identify which words to keep and which ones to avoid.
- It was also found that some texts contain multiple full stops or spaces or ‘X’ repeated multiple times. Such characters are also removed.
The model we will develop will generate a report given a combination of two images, and the report will be generated one word at a time. The sequence of previously generated words will be provided as input. Therefore, we will need a ‘first word’ to kick-off the generation process and a ‘last word’ to signal the end of the report. We will use the strings ‘startseq’ and ‘endseq’ for this purpose. These strings are added to our findings. It is important to do this now because when we encode the text, we need these strings to be encoded correctly.
The major step in encoding text is to create a consistent mapping from words to unique integer values known as tokenization. In order to get our computer to understand any text, we need to break that word or sentence down in a way that our machine can understand. We can’t work with text data if we don’t perform tokenization. Tokenization is a way of separating a piece of text into smaller units called tokens. Tokens can be either words or characters but in our case it’ll be words. Keras provides an inbuilt library for this purpose.
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(filters='!"#$%&()*+,-/:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(reports)
Now the text that we have are properly cleaned and tokenized for future use. The full code for all this is available in my GitHub account whose link is provided at the end of this story.
#encoder-decoder #deep-learning #image-captioning #attention-mechanism #artificial-intelligence #deep learning
