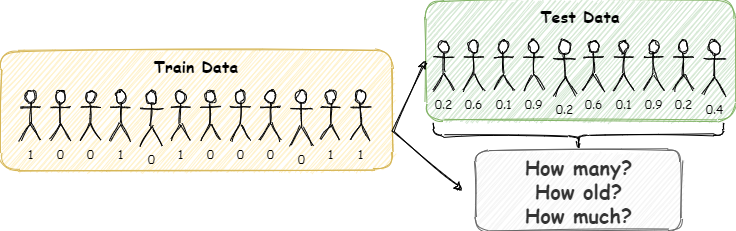
If you are reading this, then you probably tried to predict who will survive the Titanic shipwreck. This Kaggle competition is a canonical example of machine learning, and a right of passage for any aspiring data scientist. What if instead of predicting who will survive, you only had to predict how many will survive? Or, what if you had to predict the average age of survivors, or the sum of fare that the survivors paid?
There are many applications where classification predictions need to be aggregated. For example, a customer churn model may generate probabilities that a customer will churn but the business may be interested in how many customers are predicted to churn, or how much revenue will be lost. Similarly, a model may give a probability that a flight will be delayed but we may want to know how many flights will be delayed, or how many passengers are affected. Hong (2013) lists a number of other examples from actuarial assessment to warranty claims.
Most binary classification algorithms estimate probabilities that an example belongs to the positive class. If we treat these probabilities as known values (rather than estimates), then the number of positive cases is a random variable with Poisson Binomial probability distribution. (If the probabilities were all the same, the distribution would be Binomial.) Similarly, the sum of a two-value random variables where one value is a zero and the other value some other number (e.g. age, revenue) is distributed as Generalized Poisson Binomial. Under these assumptions we can report mean values as well as prediction intervals. In summary, if we had the true classification probabilities, then we could construct the probability distributions of any aggregate outcome (number of survivors, age, revenue, etc.).
Of course, the classification probabilities we obtain from machine learning models are just estimates. Therefore, treating the probabilities as known values may not be appropriate. (Essentially, we would be ignoring the sampling error in estimating these probabilities.) However, if we are interested only in the aggregate characteristics of survivors, perhaps we should focus on estimating parameters that describe the probability distributions of these aggregate characteristics. In other words, we should recognize that we have a numerical prediction problem rather than a classification problem.
In this note I compare two approaches to getting aggregate characteristics of Titanic survivors. The first is to classify and then aggregate. I estimate three popular classification models and then aggregate the resulting probabilities to get aggregate characteristics of survivors. The second approach is a regression model to estimate how aggregate characteristics of a group of passengers affect the share that survives. I evaluate each approach using many random splits of test and train data. The conclusion is that many classification models do poorly when the classification probabilities are aggregated.
#machine-learning #titanic #classification #aggregation #predictions