Whenever a data scientist works to predict or classify a problem, they first detect accuracy by using the trained model to the train set and then to the test set. If the accuracy is satisfactory, i.e., both the training and testing accuracy are good, then a particular model is considered for further development. But sometimes, models give poor results. A good machine learning model aims to generalize well from the training data to any data from that domain. So why does this happen? Here comes the major cause of the poor performance of machine learning models is Overfitting and Underfitting. Here we walk through in detail what is overfitting and underfitting and realizing the effect through Python coding and lastly, some technique to overcome these effects.
The terms overfitting and underfitting tell us whether a model succeeds in generalizing and learning the new data from unseen data to the model.
Brief information about Overfitting and Underfitting
Let’s clearly understand overfitting, underfitting and perfectly fit models.
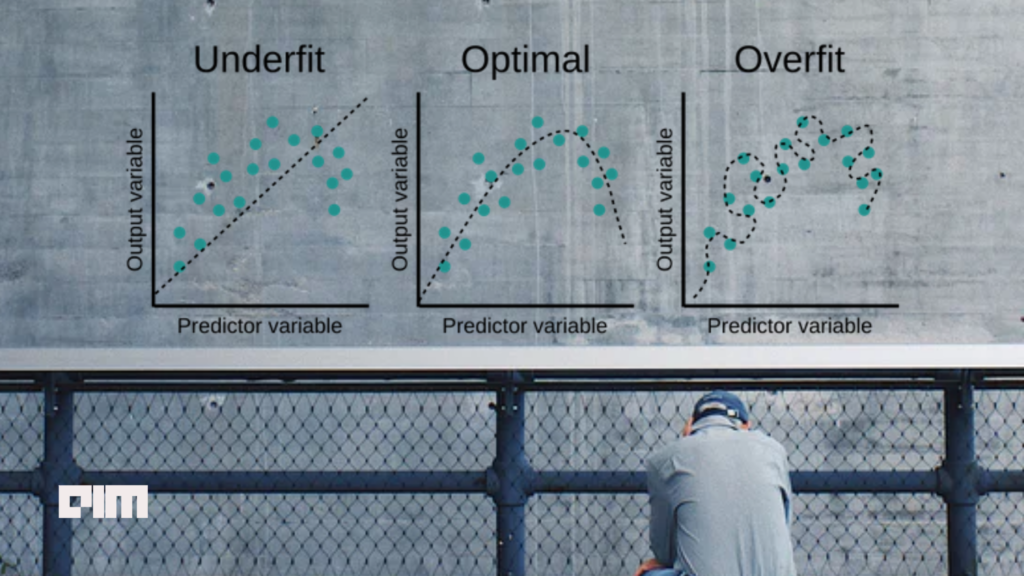
From the three graphs shown above, one can clearly understand that the leftmost figure line does not cover all the data points, so we can say that the model is under-fitted. In this case, the model has failed to generalize the pattern to the new dataset, leading to poor performance on testing. The under-fitted model can be easily seen as it gives very high errors on both training and testing data. This is because the dataset is not clean and contains noise, the model has High Bias, and the size of the training data is not enough.
When it comes to the overfitting, as shown in the rightmost graph, it shows the model is covering all the data points correctly, and you might think this is a perfect fit. But actually, no, it is not a good fit! Because the model learns too many details from the dataset, it also considers noise. Thus, it negatively affects the new data set; not every detail that the model has learned during training needs also apply to the new data points, which gives a poor performance on testing or validation dataset. This is because the model has trained itself in a very complex manner and has high variance.
The best fit model is shown by the middle graph, where both training and testing (validation) loss are minimum, or we can say training and testing accuracy should be near each other and high in value.
#developers corner #data science machine learning ai #machine learning underfitting #overfitting #underfitting