Python and its most popular data wrangling library, Pandas, are soaring in popularity. Compared to competitors like Java, Python and Pandas make data exploration and transformation simple.
But both Python and Pandas are known to have issues around scalability and efficiency.
Python loses some efficiency right off the bat because it’s an interpreted, dynamically typed language. But more importantly, Python has always focused on simplicity and readability over raw power. Similarly, Pandas focuses on offering a simple, high-level API, largely ignoring performance. In fact, the creator of Pandas wrote “ The 10 things I hate about pandas,” which summarizes these issues:

Performance issues and lack of flexibility are the main things Pandas’ own creator doesn’t like about the library. (source)
So it’s no surprise that many developers are trying to add more power to Python and Pandas in various ways. Some of the most notable projects are:
- Dask: a low-level scheduler and a high-level partial Pandas replacement, geared toward running code on compute clusters.
- Ray: a low-level framework for parallelizing Python code across processors or clusters.
- Modin: a drop-in replacement for Pandas, powered by either Dask or Ray.
- Vaex: a partial Pandas replacement that uses lazy evaluation and memory mapping to allow developers to work with large datasets on standard machines.
- RAPIDS**: **a collection of data-science libraries that run on GPUs and include cuDF, a partial replacement for Pandas.
There are others, too. Below is an overview of the Python data wrangling landscape:
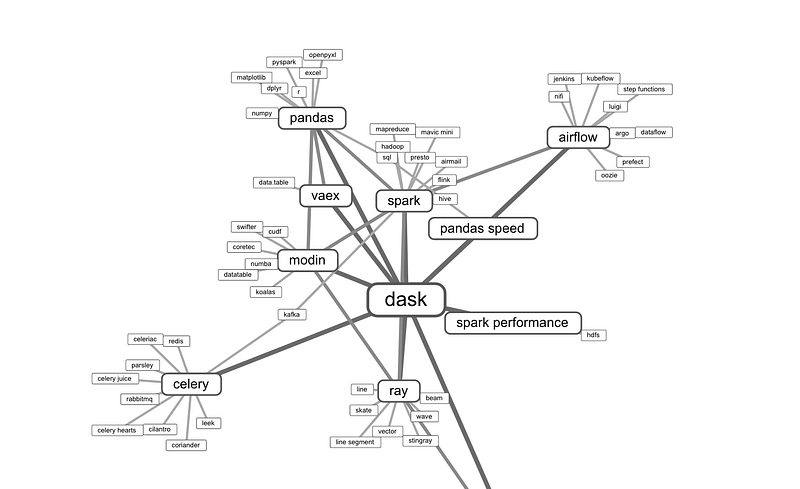
Dask, Modin, Vaex, Ray, and CuDF are often considered potential alternatives to each other. Source: Created with this tool
So if you’re working with a lot of data and need faster results, which should you use?
#pandas #data-science #programming #machine-learning #python
