Introduction
Fraudulent activities have become a rampant activity that has aroused a lot of curiosity in the financial sector. This has posed a lot of issues in helping the sector efficiently manage their customers. In this tutorial, we will be using the Dask machine learning framework to intuitively detect fraudulent transactions in the financial industry. The outcome of the model is for us to efficiently deploy in any type of bank to reduce fraudulent means by alerting the owners of the account and the bank team. The link to this code is provided on Github.
First and foremost, since this is a machine learning problem, why do we want to use dask since we have notable frameworks like pandas, bumpy, and scikit-learn to get the job done? I would love to state that dask has proven to be a framework in scaling pandas, bumpy, and scikit-learn workflow efficiently with minimal code. With dask, you get to perform all sorts of numpy, pandas, and scikit-learn operations.
Dask has proven to be a framework in scaling pandas, numpy and scikit-learn workflow efficiently with minimal code
In this tutorial, we want to build a model from a set of information provided by Bank A from their customer database; in identifying fraudulent transactions from non-fraudulent transactions. This bank has data of customers whose accounts got involved in fraudulent acts and those whose accounts do not have fraudulent history. We will be leveraging this information in predicting fraudulent accounts based on certain features.
Alright, to get started, I will be using a dataset available on kaggle here. We will be going through the following procedures for solving this problem:
- Understanding our data
- Data analysis/preprocessing with dask pandas and numpy framework.
- Data visualization with seaborn and matplotlib.
- Feature engineering
- Predictive Modelling using the Dask ML framework.
With dask, you get to perform all sorts of numpy, pandas and scikit-learn operations.
Data Analysis
In this section, we will get to understand our data and perform basic data preprocessing and cleaning using dask while we make decisions on which feature is relevant to modeling the problem. First and foremost, let’s import all libraries and load the dataset by doing this:
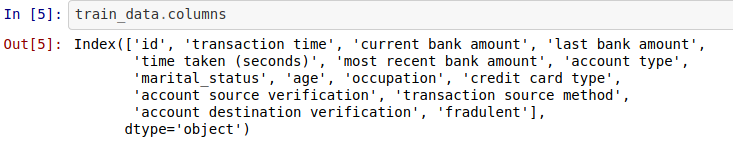
You can read in data into a dataframe in dask by using the read_csv method and then pass in the csv file. You can go ahead to see the top 5 entries in the data by using the **.head **attribute of the dataframe. The next for us is to know the features we are working with. In dask, to do this, you can run the dataframe and the column attribute. This is illustrated in the code below.
cols
With this, we can say we have an idea of what our data is all about. So our data contains information on transaction time, the current bank amount, last bank amount, time is taken to process a transaction, account type, marital status, and other information provided from each user of the bank. More importantly, we have the feature we are trying to predict or understand with respect to other features which is fraudulent; that is our target feature. We still need to know more about our data so that we can know how to analyze, select the best feature, and transform for perfect modeling. The next thing you may want to do is to have a look at the descriptive analysis of the numerical entries in our data. Dask helps us to do this efficiently by running the code below, and we will have the corresponding output.
#dask #machine-learning #data-analytics #artificial-intelligence #finance #data analytic
