Word embeddings are dense vector representations of words trained from document corpora. They have become a core component of natural language processing (NLP) downstream systems because of their ability to efficiently capture semantic and syntactic relationships between words. A widely reported shortcoming of word embeddings is that they are prone to inherit stereotypical social biases exhibited in the corpora on which they are trained.
The problem of how to quantify the mentioned biases is currently an active area of research, and several different fairness metrics have been proposed in the literature in the past few years.
Although all metrics have a similar objective, the relationship between them is by no means clear. Two issues that prevent a clean comparison is that they operate with different inputs (pairs of words, sets of words, multiple sets of words, and so on) and that their outputs are incompatible with each other (reals, positive numbers, range, etc.). This leads to a lack of consistency between them, which causes several problems when trying to compare and validate their results.
We propose the Word Embedding Fairness Evaluation (WEFE) as a framework for measuring fairness in word embeddings, and we released its implementation as an open-source library.
Framework
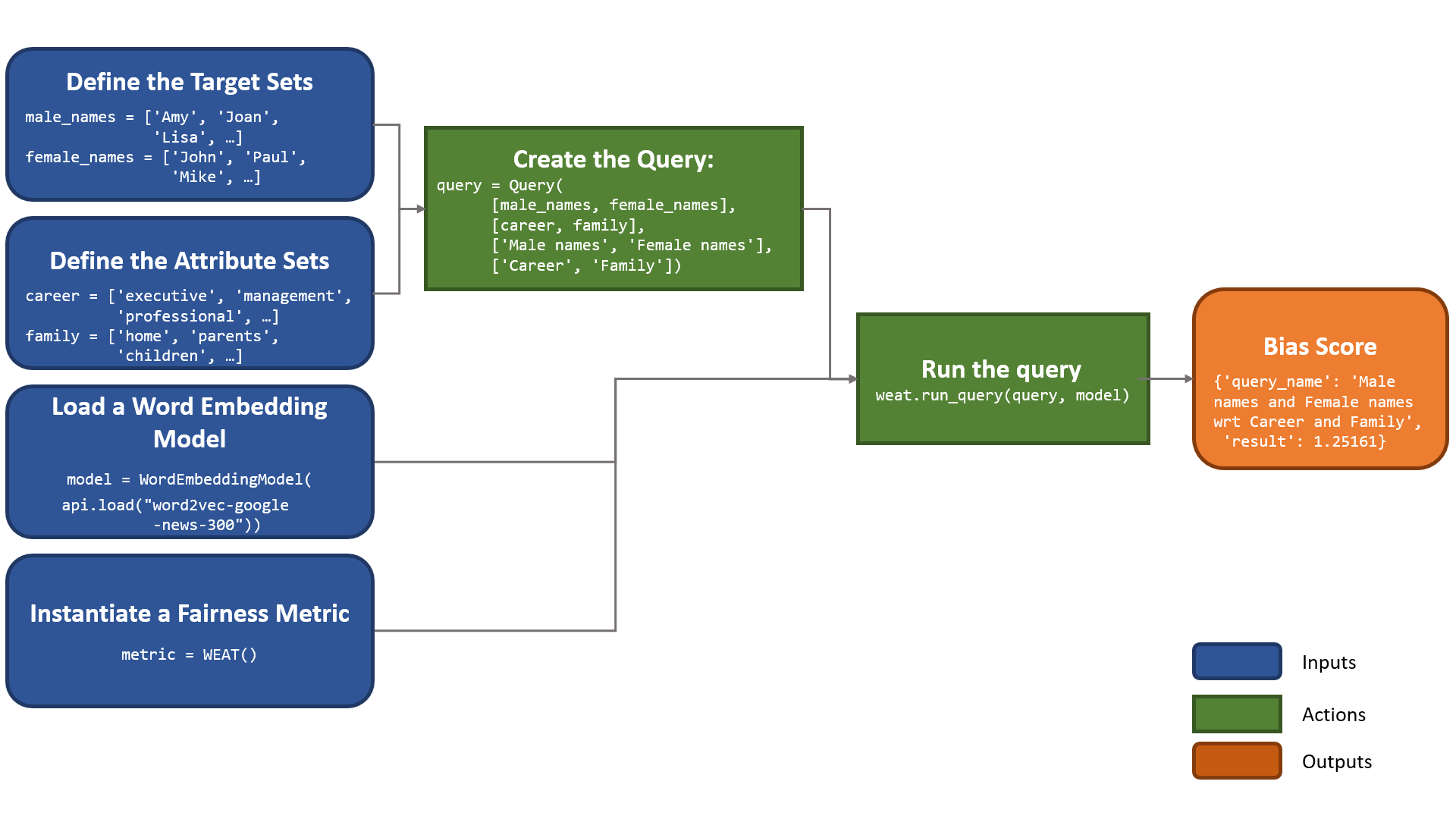
We propose an abstract view of a fairness metric as a function that receives queries as input, with each query formed by a target and attribute words. The target words describe the social groups in which fairness is intended to be measured (e.g., women, white people, Muslims), and the attribute words describe traits or attitudes by which a bias towards one of the social groups may be exhibited (e.g., pleasant vs. unpleasant terms). For more details on the framework, you can read our recently accepted paper IJCAI paper [1].
WEFE implements the following metrics:
- Word Embedding Association Test (WEAT)
- Relative Norm Distance (RND)
- Relative Negative Sentiment Bias (RNSB)
- Mean Average Cosine (MAC)
#bias #ethics #machine learning #word embeddings