In the big data era, Apache Spark is probably one of the most popular technologies as it offers a unified engine for processing enormous amount of data in a reasonable amount of time.
In this article, I am going to cover the various entry points for Spark Applications and how these have evolved over the releases made. Before doing so, it might be useful to go through some basic concepts and terms so that we can then jump more easily to the entry points namely SparkSession, SparkContext or SQLContext.
Spark Basic Architecture and Terminology
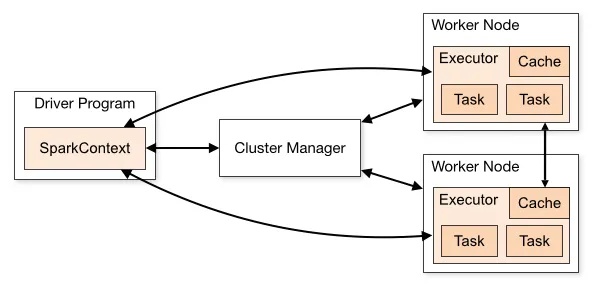
A Spark Application consists of a Driver Program and a group of Executors on the cluster. The Driver is a process that executes the main program of your Spark application and creates the SparkContext that coordinates the execution of jobs (more on this later)**. **The executors are processes running on the worker nodes of the cluster which are responsible for executing the tasks the driver process has assigned to them.
The cluster manager (such as Mesos or YARN) is responsible for the allocation of physical resources to Spark Applications.
#software-development #big-data #data-science #spark #programming