Consider a scenario where data objects are continuously being ingested at raw-data bucket. This data is periodically processed and stored at processed-data bucket. Our interest is to find a way how to track which new objects are unprocessed and process them. This in order to escape processing the same objects many times. Consider the below setup of AWS services as a response to this scenario.
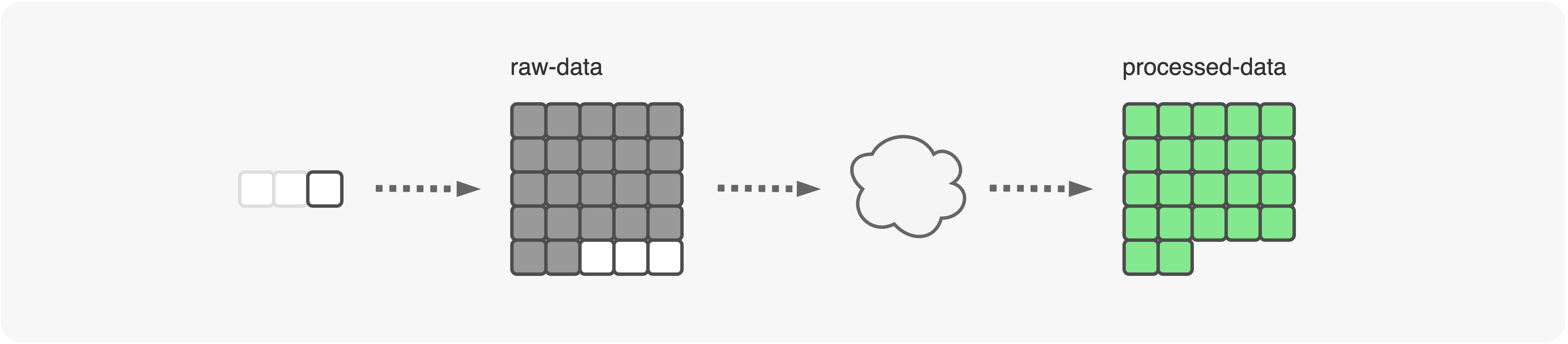
Primary setup of services
With a cloud, I have abstracted all different AWS services (EMR, Lambda, EC2 etc.) that you can use to process data. Squares represent data objects and their color represents their state as described in the figure below.

#programming #data-engineering #data-sceince #aws

3.10 GEEK