The performance of an automated machine learning(AutoML) workflow depends on how we process and feed different types of variables to the model, due to most machine learning models only accept numerical variables. Thus, categorical features encoding becomes a necessary step for any automated machine learning approaches. It not only elevates the model quality but also helps in better feature engineering.
There are two major feature reduction strategies: principal component analysis(PCA) and feature selection.
PCA strategy:
PCA is widely used in current AutoML frameworks, due to it often used for reducing the dimensionality of a large dataset so that it becomes more practical to apply machine learning where the original data are inherently high dimensional. It relies on linear relationships between feature elements and it’s often unclear what the relationships, as it also “hides” feature elements that contribute little to the variance in the data, it can sometimes eradicate a small but significant differentiator that would affect the performance of a machine learning model.
The withdraw of PCA is more apparent when AutoML system coping with categorical features. Most AutoML frameworks are using Onehot algorithm, which will easily generate high dimension dummies features when a categorical feature has large categories. That will cause information loss and hard to tune without manual diagnosis and interruption.
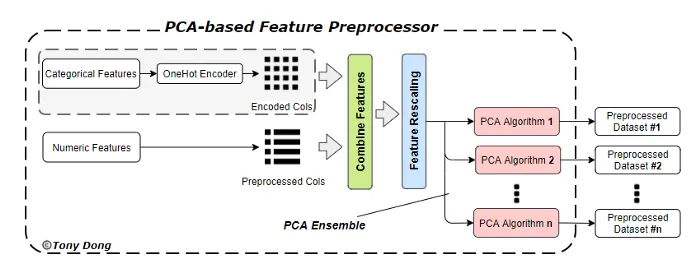
Typical PCA-based feature preprocessor uses only one encoder to cope with categorical features and has at least one PCA algorithm to implement feature reduction. This preprocessor system is widely applied in AutoML frameworks, i.e. _Auto-ML _and H2O autoML. And Auto-Sklearn has a PCA ensemble component in it, which allows multiple PCA algorithms to generate input datasets for different pipelines.
#optimalflow #data-preprocessing #automl #data-science