Existing (deep or shallow) anomaly detection methods are typically designed as unsupervised learning (trained on fully unlabeled data) or semi-supervised learning (trained on exclusively labeled normal data) due to the lack of large-scale labeled anomaly data. As a result, they are difficult to leverage prior knowledge (e.g., a few labeled anomalies) when such information is available as in many real-world anomaly detection applications. These limited labeled anomalies may originate from a deployed detection system, e.g., a few successfully detected network intrusion records, or they may be from users, such as a small number of fraudulent credit card transactions that are reported by clients and confirmed by the banks. As it is assumed only a very small number of labeled anomalies are available during training, the approaches in this research line may be grouped under the umbrella ‘few-shot anomaly detection’. However, they also have some fundamental differences from the general few-shot learning. I will discuss more on the differences at the end. In this post, I will share some of our exciting work on leveraging deep learning techniques to address this problem.
The Research Problem
Given a set of large normal (or unlabeled) training data and a very limited number of labeled anomaly data, we aim to properly leverage those small labeled anomaly data and the large normal/unlabeled data to learn an anomaly detection model.
Deep Distance-based Anomaly Detection Approach
REPEN [1] is probably the first deep anomaly detection method that is designed to leverage the few labeled anomalies to learn anomaly-informed detection models. The key idea in REPEN is to learn feature representations such that anomalies have a larger nearest neighbor distance in a random data subsample than normal data instances. This random nearest neighbor distance is one of the most effective and efficient anomaly measures, as shown in [2, 3]. REPEN aims to learn feature representations that are tailored to this state-of-the-art anomaly measure. The framework of REPEN is illustrated as follows.
The Framework of REPEN
REPEN is enforced to learn a larger nearest neighbor distance of the anomaly x- than the normal instance x+ in a random data subset x_i, …, x_{i+n-1}. The overall objective is given as
where Q is the random data subset sampled from the unlabeled/normal training data, f is a neural network-enabled feature learning function, nn_dist returns the nearest neighbor distance of x in the data subset Q.
As you can see above, REPEN can work when the large training data contains either only normal data or fully unlabeled data. In the latter case and we also do not have the labeled anomaly data, REPEN uses some existing anomaly detectors to produce some pseudo-labeled anomaly data. So, REPEN can also work in an fully unsupervised setting.
Although the labeled anomaly data is limited, REPEN can achieve very remarkable accuracy performance when compared with its unsupervised version. Some of the impressive results can be found below. The AUC performance increases quickly as the number of labeled anomalies increases from 1 to 80.
Deep Deviation Network: An End-to-end Anomaly Detection Optimization Approach
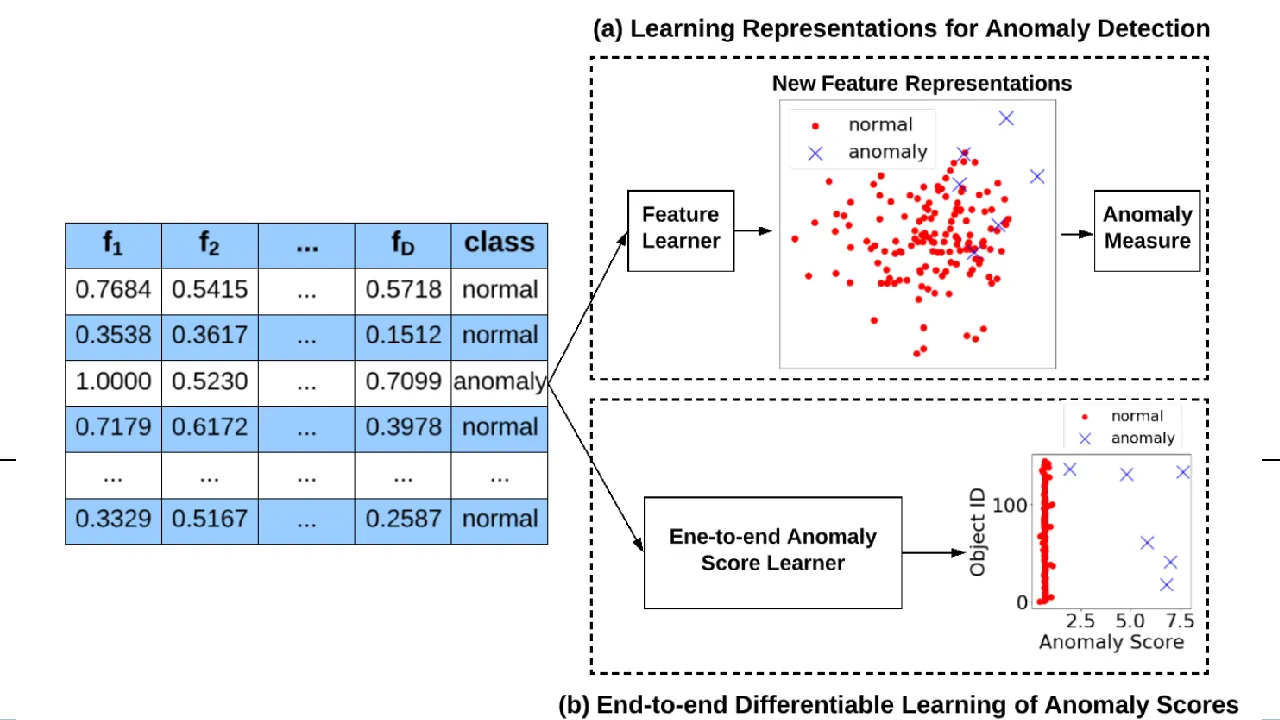
Unlike REPEN that focuses on feature representation learning for the distance-based anomaly measure, deviation network — DevNet [4] — is designed to leverage the limited labeled anomaly data to perform end-to-end anomaly score learning. The key difference can be seen in the figure below, where the former optimizes the representations while the latter optimizes the anomaly scores.
#few-shot-learning #editors-pick #anomaly-detection