INTRODUCTION
**Vehicle loans are one such type where the banks offer money to their customers to purchase a car and the customer agrees to pay back the full loan amount along with some interest, which is a source of profit to the bank. So, it is important to build a model to predict the credit risk of vehicle loan, based on its dependable factors. **In today’s world of economic expansion, credit risk is the biggest risk banks face. Vehicle loans are loans offered by the banks to their customers to purchase a vehicle where the customer agrees to terms and conditions that include repayment of the full loan amount along with the interests. This interest amount is actually a source of income to the bank. Population rich countries like India and China where population is huge, have loads of loan filing claims which are on hold and need approvals. Loan approval is a heavy task for banks because approving a loan for a defaulter might lead to loss of profit and refusal of loan to a non-defaulter might also lead to loss of profits for the bank. Hence, banks rely on such prediction model so that they could gain knowledge on figuring out as to whom the loan should be granted. It reminds me of how my father was denied a vehicle loan in the early 80’s. Hence, it is very essential for a data analyst to build a predictive model to forecast the possibility of credit risk based on certain dependable factors.
DATA MINING METHODOLOGIES
A. Logistic regression
The main mathematical concept that functions the logistic regression is the logit function which is the natural logarithm of an odd-even ratio [11]. It can be well explained by taking into consideration a distribution of one dichotomous outcome variable is paired with another dichotomous variable. Generally logistic regression is well matched for sketching and testing hypotheses about relationships between a categorical outcome variable and with one or more categorical or continuous predictor attributes. The simplest logistic regression is of the form
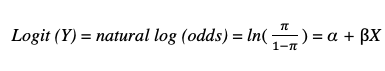
Where β is the regression coefficient, α is the Y intercept and _e _= 2.71828 is the base of the system of natural logarithms. _X _can be either continuous or categorical based on the chosen dataset, but _Y _is always categorical.
Logistic regression is a strong tool which allows simultaneous analysis of multiple explanatory variables thereby reducing the effect of confounding factors [10]. In this paper I have chosen logistic regression to predict the vehicle loan credit risk since the outcome is dichotomous like, if the loan is given, will the customer be a defaulter or non-defaulter.
Logistic regression is a strong tool which allows simultaneous analysis of multiple explanatory variables thereby reducing the effect of confounding factors [10]. In this paper I have chosen logistic regression to predict the vehicle loan credit risk since the outcome is dichotomous like, if the loan is given, will the customer be a defaulter or non-defaulter.
B. DECISION TREE
In this paper, I have considered decision tree to be applied to the vehicle loan credit risk problem which is a classification type of problem. Generally, classification is a task of assigning the object attributes into categorical attributes.

classification of object attributes into categories
We already know that a normal tree contains root, branches and leaves. This same structure is followed in decision tree algorithm. It comprises of the root node, branches and the leaf nodes. When a test is required to be done on a specific attribute, it is done on the every internal node and the result of the test is on branch and class label similar to a result in a leaf node [12]. The top most node in a tree is the parent node. Hence a decision tree is a tree where, each node is compared to a different attribute, each connection link to a branch through a decision rule and each leaf shows a result of the continuous or categorical value. It is based on the similarity of human level thinking and so it’s easy to make use of the data and make effective interpretations. The whole idea is to create a tree of the entire data and determine a solitary result at every leaf based on the objective of the problem. Below is one such example of how the decision tree algorithm is related to real-time problems faced.
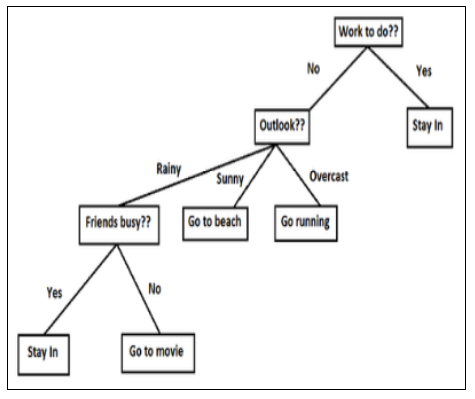
The decision tree with an example statement
Hence, I have adopted the decision tree algorithm to make decisions on whether to approve vehicle loan for the customer’s claims or not.
DATA PREPROCESSING AND TRANSFORMATION
It’s always better to pre-process the data before we build a model. The pre-processing of the data includes checking the presence of missing values, detection of outliers if any and the univariate and bivariate analyses.
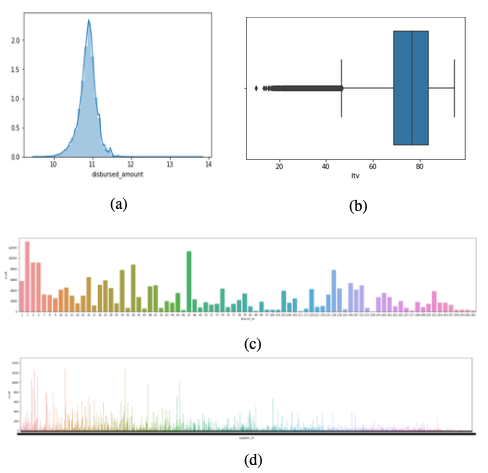
The dataset that I have collected for vehicle loan credit risk prediction consists of 233,154 rows and 40 different variables that might affect the prediction of the defaulters. The summary of the dataset is as follows,
#decision-tree #predictions #machine-learning #logistic-regression #deep learning