This article presents our research on high resolution image generation using Generative Variational Autoencoder.
Important Points
- Our work addresses the mode collapse issue of GANs and blurred images generated using VAEs in a single model architecture.
- We use the encoder of VAE as it is while replacing the decoder with a discriminator.
- The encoder is fed data from a normal distribution while the generator is fed that from a gaussian distribution.
- The combination from both is then fed to a discriminator which tells whether the generated images are correct or not.
- We evaluate our network on 3 different datasets: MNIST, fashion MNIST and TCIA Pancreas CT dataset.
- Evaluation on MNIST, Fashion MNIST and TCIA Pancreas CT shows we outperform all previous state-of-the-art methods in terms of MMD, SSIM, log likelihood, reconstruction error, ELBO and KL divergence as the evaluation metrics.
Introduction
The training of deep neural networks requires hundreds or even thousands of images. Lack of labelled datasets especially for medical images often hinders the progress. Hence it becomes imperative to create additional training data. Another area which is actively researched is using generative adversarial networks for image generation. Using this technique, new images can be generated by training on the existing images present in the dataset. The new images are realistic but different from the original data. There are two main approaches of using data augmentation using GANs: image to image translation and sampling from random distribution. The main challenge with GANs is the mode collapse problem i.e. the generated images are quite similar to each other and there is not enough variety in the images generated.
Another approach for image generation uses Variational Autoencoders. This architecture contains an encoder which is also known as generative network which takes a latent encoding as input and outputs the parameters for a conditional distribution of the observation. The decoder is also known as an inference network which takes as input an observation and outputs a set of parameters for the conditional distribution of the latent representation. During training VAEs use a concept known as reparameterization trick, in which sampling is done from a gaussian distribution. The main challenge with VAEs is that they are not able to generate sharp images.
Dataset
The following datasets are used for training and evaluation:
- MNIST — This is a large dataset of handwritten digits which has been used successfully for training image classification and image processing algorithms. It contains 60,000 training images and 10,000 test images.
- Fashion MNIST — This dataset is also similar to MNIST with 60,000 training images and 10,000 test images. Each example is a 28x28 grayscale image which is labelled into one of the 10 classes of fashion wear like trouser, top, sandal etc.
- TCIA Pancreas CT — The National Institutes of Health Clinical Center performed 82 abdominal contrast enhanced 3D CT scans. The CT scans have resolutions of 512×512 pixels with varying pixel sizes and slice thickness between 1.5 to 2.5 mm.
VAEs vs GANs vs Ours
We show how instead of inference made in the way shown in original VAE architecture, we can add the error vector to the original data and multiply by standard distribution. The new term goes to the encoder and gets converted to the latent space. In the decoder, similarly the error vector gets added to the latent vector and multiplied by standard deviation. In this manner, we use the encoder of VAE in a manner similar to that in the original VAE. While we replace the decoder with a discriminator and hence change the loss function accordingly. The comparison between model architectures of VAE and our architecture is shown in Fig 1.
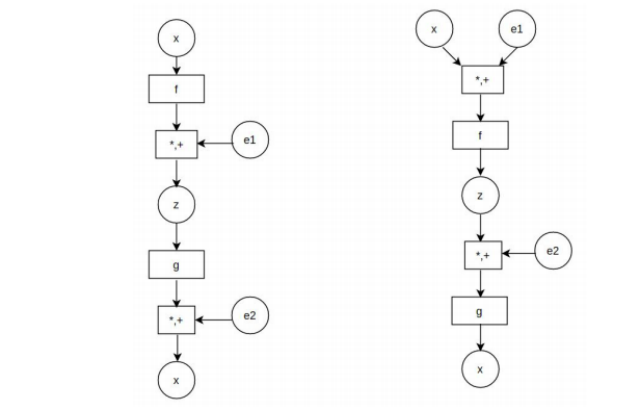
Figure 1: Comparison between standard VAE and our Model
Our architecture can be seen both as an extension of VAE as well as that of GAN. Reasoning it as the former is easy as this requires a change in loss function for decoder, while the latter can be made by recalling the fact that GAN essentially works on the concept of zero sum game maintaining Nash Equilibrium between the generator and discriminator. In our case, both the encoder from VAE and discriminator from GAN are playing zero sum game and are competing with each other. As the training proceeds, the loss decreases in both the cases until it stabilizes.
#data-science #artificial-intelligence #deep-learning #machine-learning #neural-networks #deep learning
