Continue our journey to know Reinforcement Learning in a fun way with AWS and Jakarta Machine Learning. We have discussed AWS Deep Racer and the basics of Reinforcement Learning (RL) in the first article. For you who haven’t read this article or want to reread it, don’t worry.
Now, in this article, we will discuss how to formulate the RL problems. To do that, we need to understand the Markov Decision Process or well known as MDP.
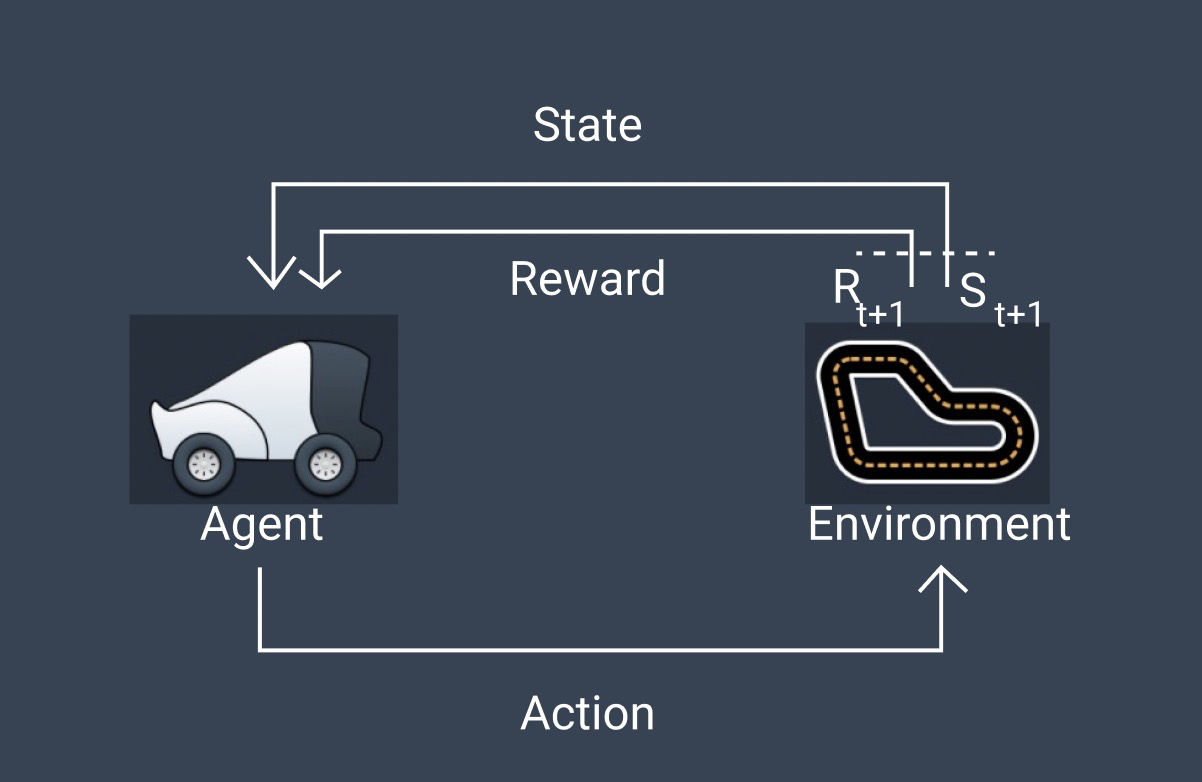
Typical Reinforcement Learning Process. Image by Author
MDP is a framework that can be used to formulate the RL problems mathematically. Almost all RL problems can be modeled as MDP with states, actions, transition probability, and the reward function.
So, why we need to care about MDP? Because with the MDP, an agent can get an optimal policy for maximum rewards over time, and we will get optimum results.
Okay, Let’s get started. To get a better understanding of MDP, we need to learn about the components of MDP first.
Markov Property
The future depends only on the present and not on the past.
That statement summarises the principle of Markov Property. On the other hand, the term Markov Property refers to the memoryless property of a stochastic — or randomly determined — a process in probability theory and statistics.
As an example, let say you own a restaurant and manage the raw material inventory. You check the inventory each week and use the result to order the raw material for next week. This condition implies that you only consider the stock this week to predict next week’s requirement without bothering last week’s stock level.
#reinforcement-learning #deepracer #data-science #artificial-intelligence #markov-decision-process