There are many tasks in NLP from text classification to question answering, but whatever you do the amount of data you have to train your model impacts the model performance heavily.
What can you do to make your dataset larger?
Simple option -> Get more data :)
But acquiring and labeling additional observations can be an expensive and time-consuming process.
What you can do instead?
Apply data augmentation to your text data.
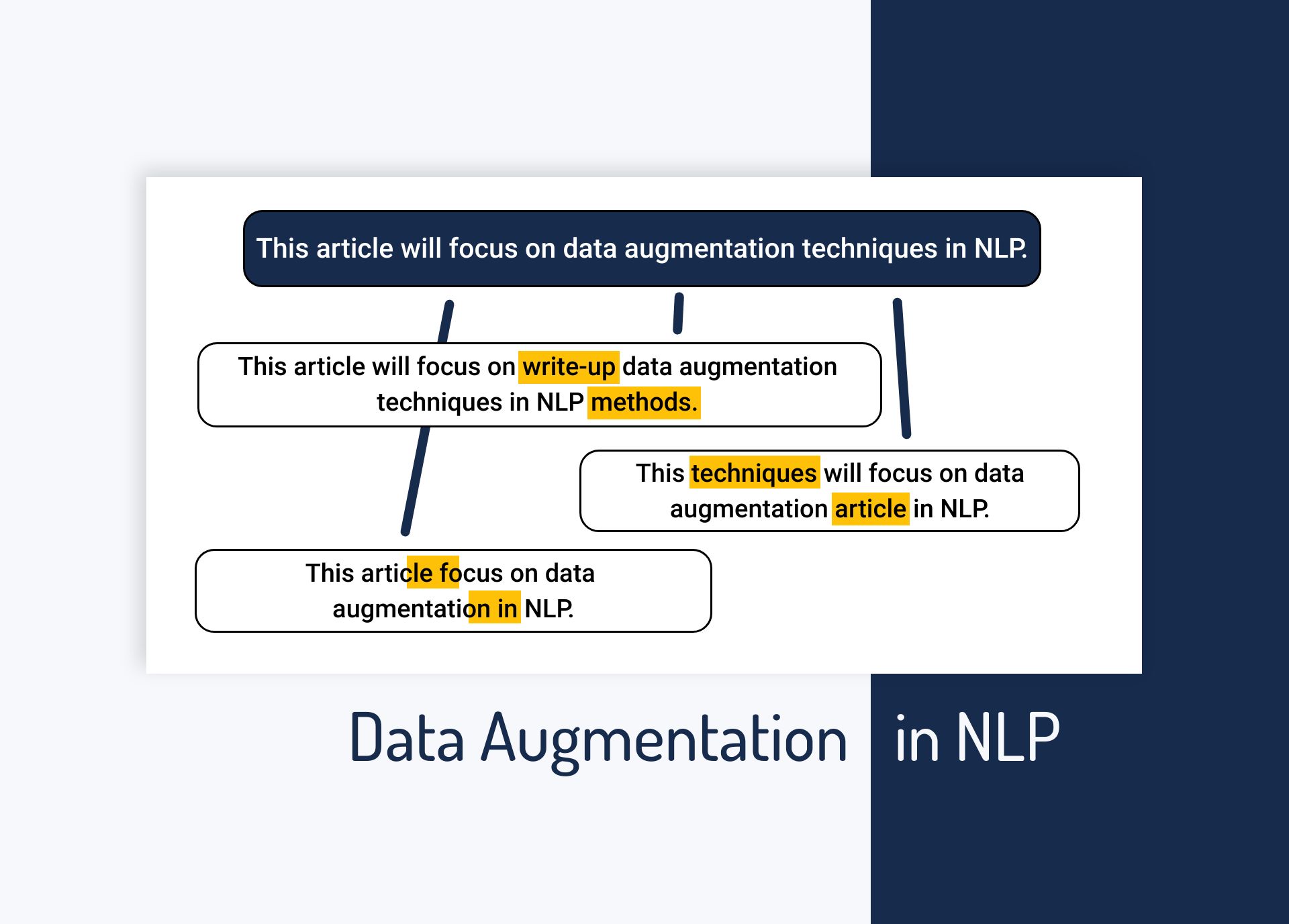
Data augmentation techniques are used to generate additional, synthetic data using the data you have. Augmentation methods are super popular in computer vision applications but they are just as powerful for NLP.
In this article, we’ll go through all the major data augmentation methods for NLP that you can use to increase the size of your textual dataset and improve your model performance.
Data augmentation for computer vision vs NLP
In computer vision applications, data augmentations are done almost everywhere to get larger training data and make the model generalize better.
The main methods used involve:
- cropping
- flipping
- zooming
- rotation
- noise injection
In computer vision, these transformations are done on the go using data generators. As a batch of data is fed to your neural network it is randomly transformed (augmented). You don’t need to prepare anything before training.
This isn’t the case with NLP, where data augmentation should be done carefully due to the grammatical structure of the text. The methods discussed here are used **before training. **A new augmented dataset is generated beforehand and later fed into data loaders to train the model.
#machine-learning #data-augmentation #nlp #data-science #kaggle #artificial-intelligence