In the first part of this series, we’ve learned about some important terms and concepts in Reinforcement Learning (RL). We’ve also learned how RL works at a high-level.
Before we dive deeper into the theory behind RL, I want to explain more about RL based on its SUPER cool application, AWS DeepRacer.
What is AWS DeepRacer?
AWS DeepRacer is an autonomous 1/18th scale race car designed to test RL models by racing on a physical track. There are three race types in AWS DeepRacer:
- Time trial — The agent races against the clock on a well-marked track without stationary obstacles or moving competitors.
- Object avoidance — The vehicle races on a two-lane track with a fixed number of stationary obstacles placed along the track.
- Head-to-head racing — The vehicle races against other moving vehicles on a two-lane track.
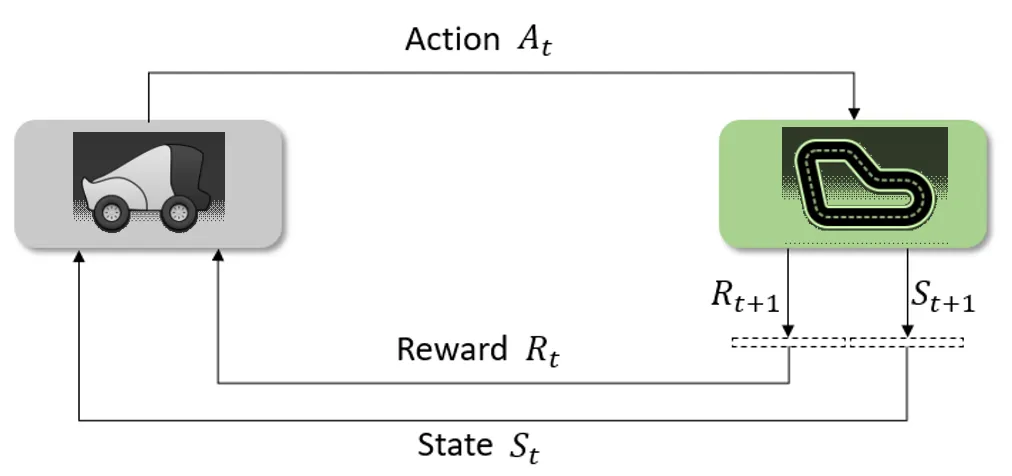
Reinforcement Learning in AWS DeepRacer
I assumed you are familiar with how RL works at a high-level. If you don’t, please check the first article of this series to learn more about that.
In AWS DeepRacer, we want our vehicle (agent) to race by itself in a track (environment) while also gaining the maximum cumulative total reward so that we can achieve our goal — to win a race against the clock, or to avoid all of the obstacles, or to win a race against another vehicle.
Therefore, it is categorized as an episodic task where the terminal state could be the finish line or out of the track.
What about the state? Here, a state is an image captured by the front-facing camera on the vehicle. The vehicle will take images (160x120) at around 15 fps.
#machine-learning #reinforcement-learning #data-science