Machine learning (ML) is “an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed.” ML algorithms are used to find patterns in data that generate insight and help make data-driven decisions and predictions. These types of algorithms are employed every day to make critical decisions in medical diagnosis, stock trading, transportation, legal matters and much more. Therefore, it can be seen why data scientists place ML on such a high pedestal; it provides a medium for high priority decisions, that can guide better business and smart actions, in real-time without human intervention.
Now, ML models do not necessarily ‘learn’ like how humans learn. Rather, these algorithms use computational methods to understand information directly from data without relying on a predetermined equation as a model. To do this, the algorithms are made to determine a pattern in data and develop a target function which best maps an input variable, x, to a target variable, y. It must be noted here that the true form of the target function is usually unknown. If the function was known, then ML would not be needed.
Therefore, the idea is to determine the best estimate of this target function by conducting sound inference about the sample data to then apply and optimize the appropriate ML technique for the situation at hand. Different situations require that different assumptions be made about the form of the function being estimated. Additionally, different ML algorithms make different assumptions about the shape the function, and thus, how it should be optimized. Understandably, it is easy to get overwhelmed with how much there is to learn with ML. So, in this post, I discuss two important topics in ML that every data scientist should know.
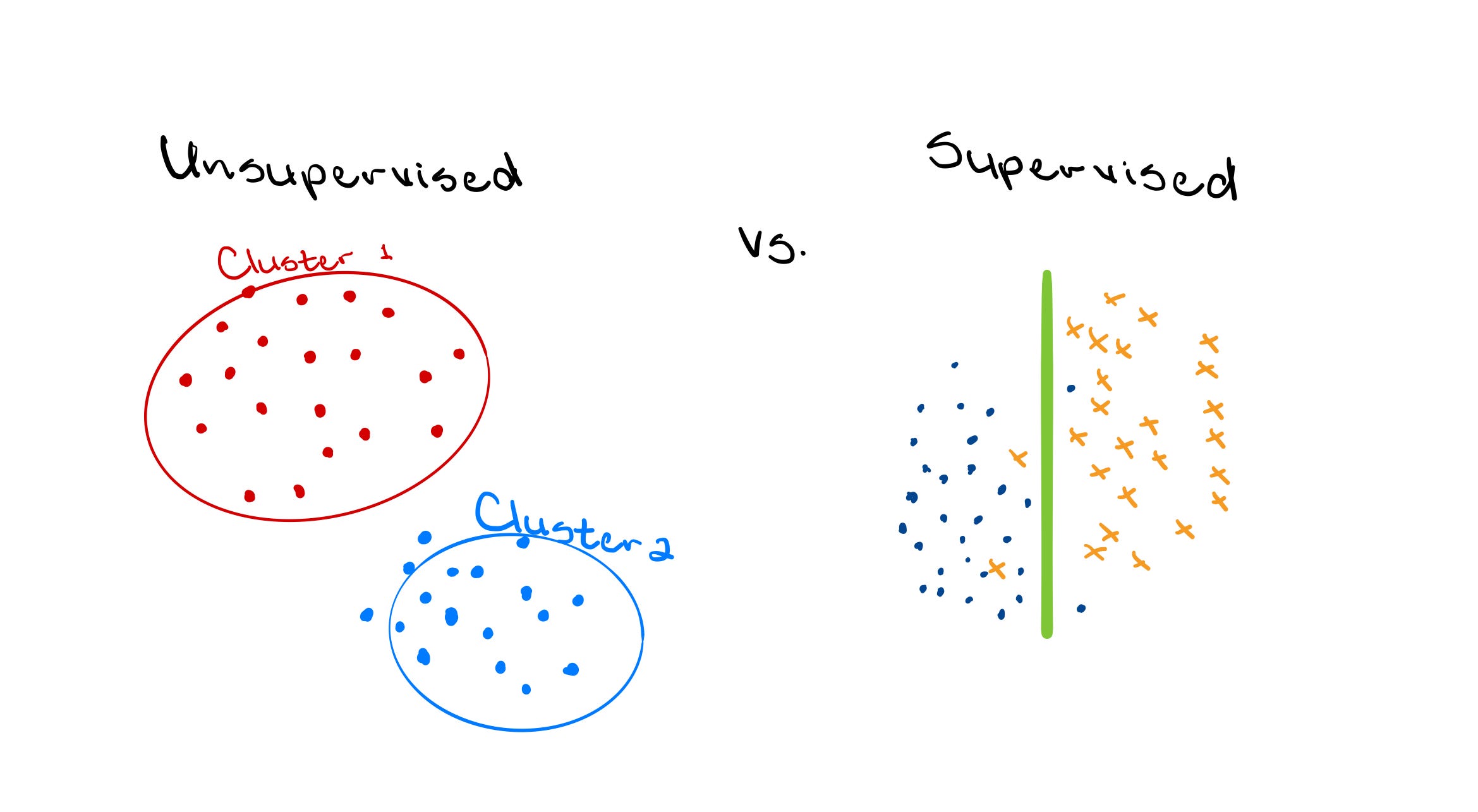
#artificial-intelligence #machine-learning #towards-data-science #programming #data-science
