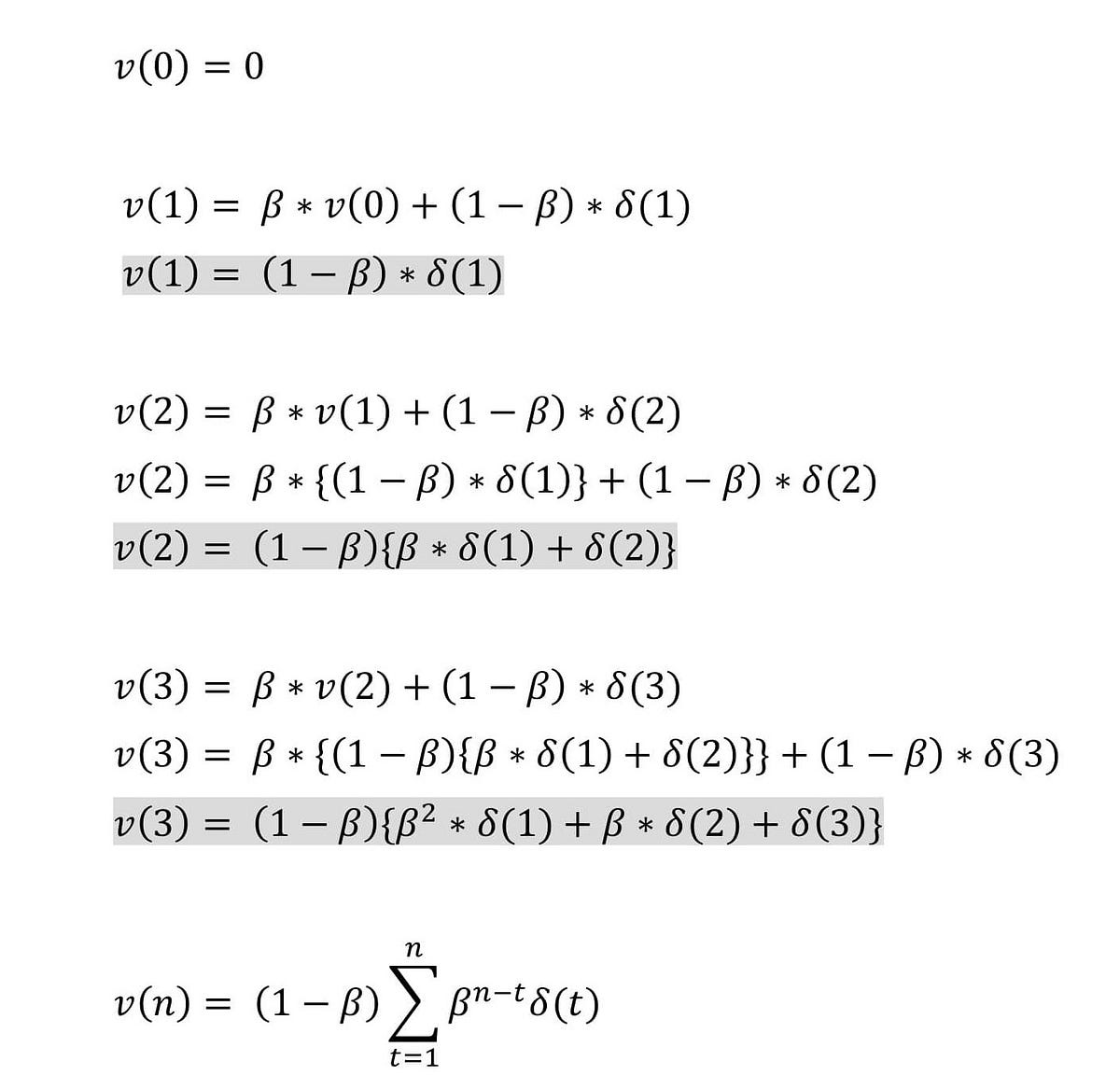The problem with vanilla gradient descent is that the weight update at a moment (t) is governed by the learning rate and gradient at that moment only. It doesn’t take into account the past steps taken while traversing the cost space.
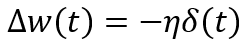
Image by author
It leads to the following problems.
- The gradient of the cost function at saddle points( plateau) is negligible or zero, which in turn leads to small or no weight updates. Hence, the network becomes stagnant, and learning stops
- The path followed by Gradient Descent around a steep valley is very jittery even when operating with mini-batch mode
Consider the below cost surface.
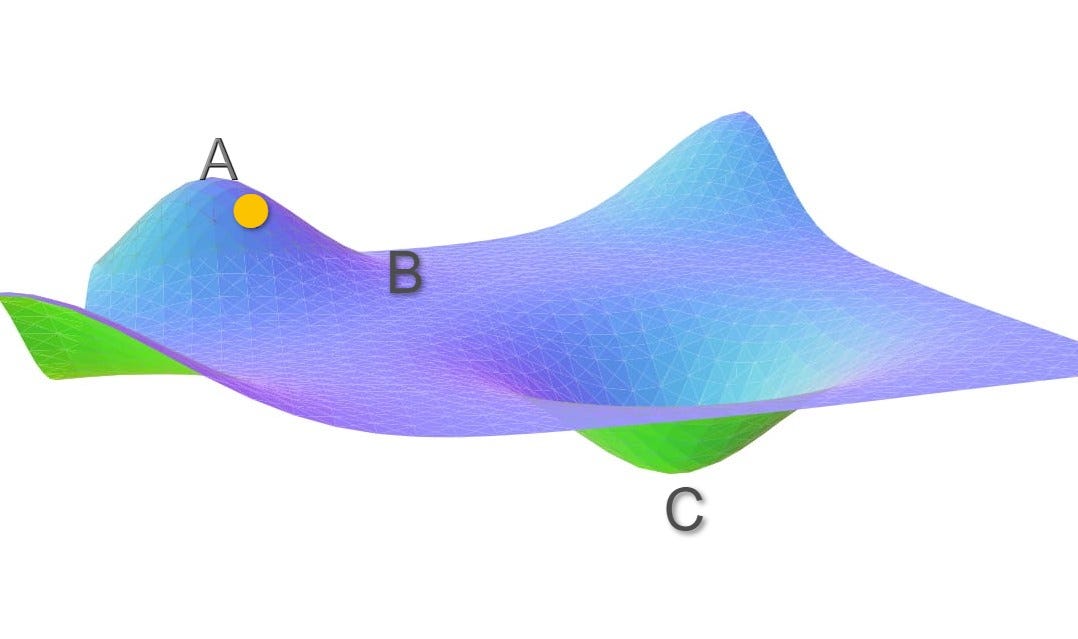
Image by author
Let’s assume the initial weights of the network under consideration correspond to point A. With vanilla gradient descent, the Loss function decreases rapidly along the slope AB as the gradient along this slope is high. But as soon as it reaches point B the gradient becomes very low. The weight updates around B is very small. Even after many iterations, the cost moves very slowly before getting stuck at a point where the gradient eventually becomes zero.
In this case, ideally, cost should have moved to the global minima point C, but because the gradient disappears at point B, we are stuck with a sub-optimal solution.
#machine-learning #momentum #mathematics #optimisation #gradient-descent