In the 1940s, mathematical programming was synonymous with optimization. An optimization problem included an objective function that is to be maximized or minimized by choosing input values from an allowed set of values [1].
Nowadays, optimization is a very familiar term in AI. Specifically, in Deep Learning problems. And one of the most recommended optimization algorithms for Deep Learning problems is Adam.
Disclaimer: basic understanding of neural network optimization. Such as Gradient Descent and Stochastic Gradient Descent is preferred before reading.
In this post, I will highlight the following points:
- Definition of Adam Optimization
- The Road to Adam
- The Adam Algorithm for Stochastic Optimization
- Visual Comparison Between Adam and Other Optimizers
- Implementation
- Advantages and Disadvantages of Adam
- Conclusion and Further Reading
- References
1. Definition of Adam Optimization
The Adam algorithm was first introduced in the paper Adam: A Method for Stochastic Optimization [2] by Diederik P. Kingma and Jimmy Ba. Adam is defined as “a method for efficient stochastic optimization that only requires first-order gradients with little memory requirement” [2]. Okay, let’s breakdown this definition into two parts.
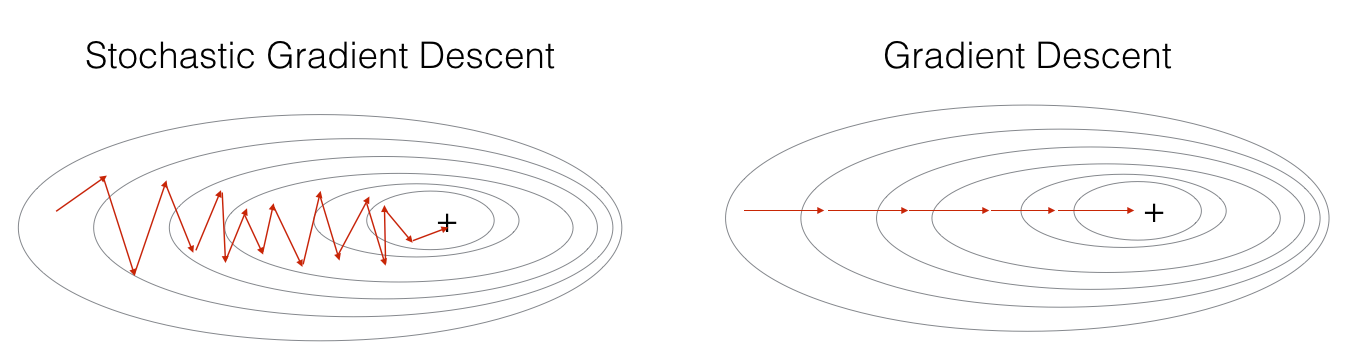
First, stochastic optimization is the process of optimizing an objective function in the presence of randomness. To understand this better let’s think of Stochastic Gradient Descent (SGD). SGD is a great optimizer when we have a lot of data and parameters. Because at each step SGD calculates an estimate of the gradient from a random subset of that data (mini-batch). Unlike Gradient Descent which considers the entire dataset at each step.
#machine-learning #deep-learning #optimization #adam-optimizer #optimization-algorithms