Overview
In my previous article, I showed how to build policy gradients from scratch in Python, and we used it to tune discrete hyperparameters for machine learning models. (If you haven’t read it already, I’d recommend starting there.) Now, we’ll build on that progress, and extend policy gradients to optimize continuous parameters as well. By the end of this article, we’ll have a full-fledged method for simultaneously tuning discrete and continuous hyperparameters.
Review of Policy Gradients
From last time, recall that policy gradients optimizes the following cost function for tuning hyperparameters:
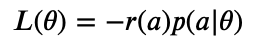
where a is the set of hyperparameters chosen for a particular experiment, and theta represents all trainable parameters for our PG model. Then, p denotes the probability of selecting action a, and r is the “reward” received for that action. We then showed that:
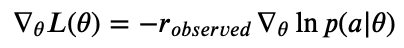
The above equation tells us how to update our PG model, given a set of actions and their observed _rewards. _For discrete hyperparameters, we directly updated the relative log-probabilities (logits) for each possible action:
from typing import Sequence, Dict, Callable
import numpy as np
from numpy import ndarray
def softmax(x: ndarray, axis: int = -1) -> ndarray:
"""Computes the probability for selecting each discrete value."""
return np.exp(x) / np.sum(np.exp(x), axis=axis, keepdims=True)
class CategoricalActor:
def __init__(self, dim: int):
self.dim = dim
# Relative log-probabilities for selecting each discrete value.
# Initialize to equal weights of 'log(1 / dim)'.
self.logits = -np.log(dim) * np.ones(dim)
def action(self) -> ndarray:
"""Performs a weighted draw of the discrete values, using 'self.logits'."""
return np.argmax(softmax(self.logits) * np.random.rand(self.dim))
def update(self, actions: ndarray, values: ndarray, lr: float = 0.1) -> None:
"""Given a batch of actions (hyperparameters) and their relative values, update
the model's internal parameters (logits) to maximize future action values."""
# Normalize values, so scaling the cost function doesn't affect training.
values = (values - values.mean()) / (values.std() + 1e-5)
values = values.reshape(-1, 1)
# Mask gradients, so that we only update parameters that were selected in 'actions'
mask = np.arange(len(self.logits)).reshape(1, -1) == actions.reshape(-1, 1)
# Gradient of log-softmax is (1 - softmax). Go ahead and multiply by 'values'.
grads = -values * (1 - softmax(self.logits)).reshape(1, -1)
# Compute gradient for each logit. Don't average over entries that were masked
# out, and avoid dividing by zero.
grad_logits = np.sum(grads * mask, axis=0) / (np.sum(mask, axis=0) + 1e-5)
self.logits += lr * grad_logits
view raw
categorical_actor.py hosted with ❤ by GitHub
This approach will not work for continuous hyperparameters, because we cannot possibly store the log-probability for every possible outcome! We need a new method for generating continuous random variables and their relative log-probabilities.
Extending to Continuous Hyperparameters
In the field of reinforcement learning, continuous variables are commonly modeled using Gaussian Processes. The idea is pretty straightforward: our model predicts the mean and standard deviation for a Gaussian distribution, and we gather actions/predictions using a random number generator.
#optimization #ai #reinforcement-learning #machine-learning #neural-networks #deep learning