Reinforcement learning is a fast-moving field. Many companies are realizing the potential of RL. Recently, Google’s DeepMind success in training RL agent AlphaGo to defeat the world Go Champion is just astounding.
But what is RL? RL is a branch of machine learning where the agent learns a behavior by trial and error. That means the agent interacts with its environment without any explicit supervision, the “desired” behavior is emphasized by a feedback signal called a reward. The agent is rewarded when taking a “good” action or it can be “punished” when it takes a “bad” action.
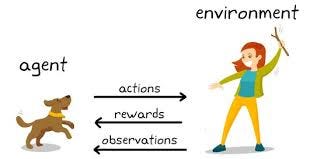
In RL terminology, observations are known as states. Hence, the agent learning path comprises a series of actions taken on states and getting rewards as feedback. At the early stages of learning, the agent doesn’t know the best action to take in a specific state, after all that is the whole learning objective.
The agent objective is to maximize the sum of the rewards in a long-term. The maximization is long-term meaning that we are not only concerned with taking actions that yield the highest immediate reward but more generally, the agent is trying to learn the best strategy that gives best cumulative reward in a long term. Some of the rewards can be delayed. This objective is described as maximizing the expected return, written in math as follows:

where R is the immediate reward and γ is known as discount factor.
When γ is closer to 0, the agent is near-sighted (gives more emphasis on the immediate reward). If the discount factor is closer to 1, the agent is more far-sighted.
The goal of RL algorithms is to estimate the expected return when the agent takes an action in a given state while following a policy. These are known as Q-values and estimate “how good” it is for the agent to take a given action in a a given state.
Q-learning is one of the most popular RL algorithms. QL allows the agent to learn the values of state-action pairs through continuous updates. As long as each state-action pair are visited and updated infinitely often, QL guarantee an optimal policy. The equation for updating the values of state-action pairs in QL is given as:

#ai #reinforcement-learning #machine-learning #sarsa #q-learning
