In this post, we’ll learn how to use Node.js and friends to perform a quick and effective web-scraping for single-page applications. This can help us gather and use valuable data which isn’t always available via APIs.
Let’s dive in.
What is web scraping?
Web scraping is a technique used to extract data from websites using a script. Web scraping is the way to automate the laborious work of copying data from various websites.
Web Scraping is generally performed in the cases when the desirable websites don’t expose the API for fetching the data. Some common web scraping scenarios are:
- Scraping emails from various websites for sales leads.
- Scraping news headlines from news websites.
- Scraping product’s data from E-Commerce websites.
Why do we need web scraping when e-commerce websites expose the API (Product Advertising APIs) for fetching/collecting product’s data?
E-Commerce websites only expose some of their product’s data to be fetched through APIs therefore, web scraping is the more effective way to collect the maximum product’s data.
Product comparison sites generally do web scraping. Even Google Search Engine does crawling and scraping to index the search results.
What will we need?
Getting started with web scraping is easy and it is divided into two simple parts-
- Scraping emails from various websites for sales leads.
- Scraping news headlines from news websites.
- Scraping product’s data from E-Commerce websites.
We will also use two open-source npm modules:
- axios— Promise based HTTP client for the browser and node.js.
- cheerio — jQuery for Node.js. Cheerio makes it easy to select, edit, and view DOM elements.
Tip: Don’t duplicate common code. Use tools like Bit to organize, share and discover components across apps- to build faster. Take a look.
Setup
Our setup is pretty simple. We create a new folder and run this command inside that folder to create a package.json file. Let’s cook the recipe to make our food delicious.
npm init -y
Before we start cooking, let’s collect the ingredients for our recipe. Add Axios and Cheerio from npm as our dependencies.
npm install axios cheerio
Now, require them in our index.js file
const axios = require('axios');
const cheerio = require('cheerio');
Make the Request
We are done with collecting the ingredients for our food, let’s start with the cooking. We are scraping data from the HackerNews website for which we need to make an HTTP request to get the website’s content. That’s where axios come into action.
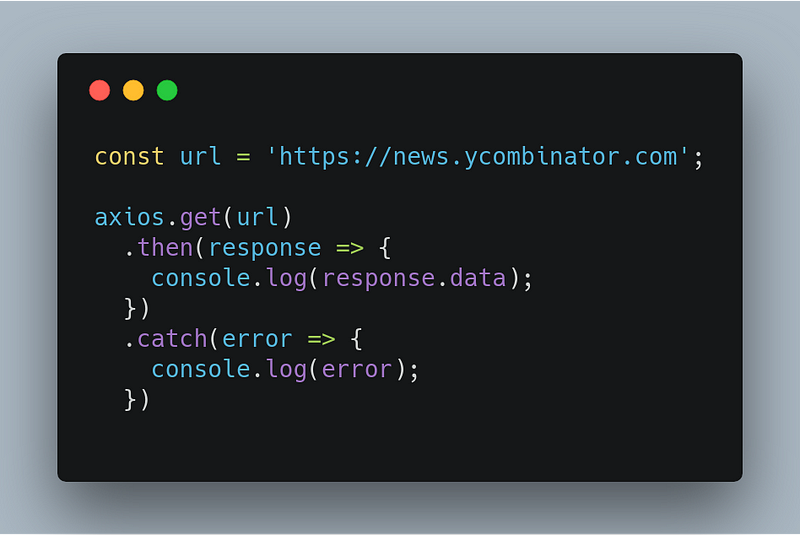
Our response will look like this —
<html op="news">
<head>
<meta name="referrer" content="origin">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" type="text/css" href="news.css?oq5SsJ3ZDmp6sivPZMMb">
<link rel="shortcut icon" href="favicon.ico">
<link rel="alternate" type="application/rss+xml" title="RSS" href="rss">
<title>Hacker News</title>
</head>
<body>
<center>
<table id="hnmain" border="0" cellpadding="0" cellspacing="0" width="85%" bgcolor="#f6f6ef">
.
.
.
</body>
<script type='text/javascript' src='hn.js?oq5SsJ3ZDmp6sivPZMMb'></script>
</html>
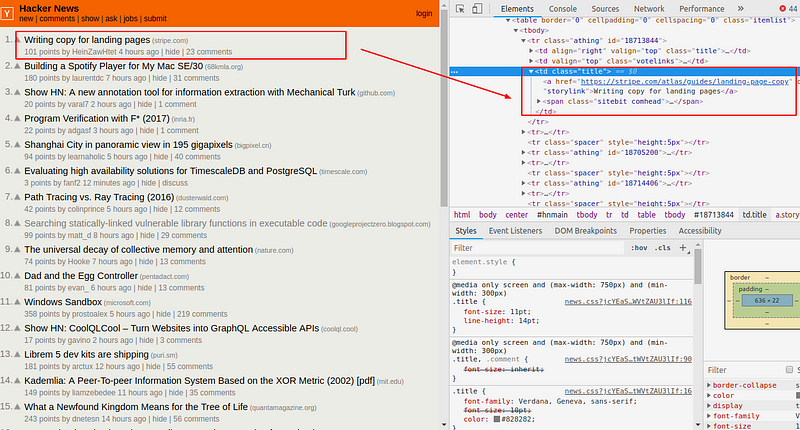
We are getting similar HTML content which we get while making a request from Chrome or any browser. Now we need some help of Chrome Developer Tools to search through the HTML of a web page and select the required data. You can learn more about the Chrome DevTools from here.
We want to scrape the News heading and its associated links. You can view the HTML of the webpage by right-clicking anywhere on the webpage and selecting “Inspect”.
Parsing HTML with Cheerio.js
Cheerio is the jQuery for Node.js, we use selectors to select tags of an HTML document. The selector syntax was borrowed from jQuery. Using Chrome DevTools, we need to find selector for news headlines and its link. Let’s add some spices to our food.
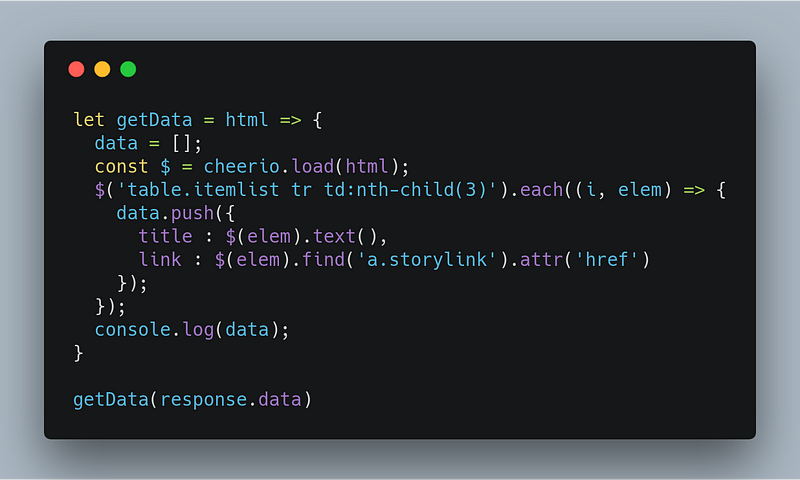
First, we need to load in the HTML. This step in jQuery is implicit since jQuery operates on the one, baked-in DOM. With Cheerio, we need to pass in the HTML document. After loading the HTML, we iterate all the occurrences of the table row to scrape each and every news on the page.
The Output will look like —
[
{
title: 'Malaysia seeks $7.5B in reparations from Goldman Sachs (reuters.com)',
link: 'https://www.reuters.com/article/us-malaysia-politics-1mdb-goldman/malaysia-seeks-7-5-billion-in-reparations-from-goldman-sachs-ft-idUSKCN1OK0GU'
},
{
title: 'The World Through the Eyes of the US (pudding.cool)',
link: 'https://pudding.cool/2018/12/countries/'
},
.
.
.
]
Now we have an array of JavaScript Object containing the title and links of the news from the HackerNews website. In this way, we can scrape the data from various large number of websites. So, our food is prepared and looks delicious too.
Now, websites are more dynamic in nature i.e content is rendered through javascript. For an instance, let’s make a request to any SPA website like I have taken this vue admin template website and disable javascript using Chrome DevTools, this is the response I got —
<html lang="tr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="https://fonts.googleapis.com/icon?family=Material+Icons" rel="stylesheet">
<link href="https://use.fontawesome.com/releases/v5.6.3/css/all.css" rel="stylesheet">
<link rel="shortcut icon" type="image/png" href="static/logo.png">
<title>Vue Admin Template</title>
<link href="static/css/app.48932a774ea0a6c077e59d0ff4b2bfab.css" rel="stylesheet">
</head>
<body data-gr-c-s-loaded="true" cz-shortcut-listen="true">
<div id="app"></div>
<script type="text/javascript" src="static/js/manifest.2ae2e69a05c33dfc65f8.js">
</script>
<script type="text/javascript" src="static/js/vendor.ef9a9a02a332d6b5e705.js">
</script>
<script type="text/javascript" src="static/js/app.3ec8db3ca107f46c3715.js">
</script>
</body>
</html>
So, the actual content that we need to scrape will be rendered within the div#app element through javascript so methods that we used to scrape data in the previous post fails as we need something that can run the javascript files similar to our browsers.
We will use web automation tools and libraries like Selenium, Cypress, Nightmare, Puppeteer, x-ray, Headless browsers like phantomjs etc.
Why these tools and libraries? These tools and libraries are generally used by Software testers in tech industries for software testing. All of these opens a browser instance in which our website can run just like other browsers and hence executes javascript files which render the dynamic content of the website.
What will we need?
As I explained in my previous post that web scraping is divided into two simple parts —
- Scraping emails from various websites for sales leads.
- Scraping news headlines from news websites.
- Scraping product’s data from E-Commerce websites.
We will be using Node.js and browser automation library:
- axios— Promise based HTTP client for the browser and node.js.
- cheerio — jQuery for Node.js. Cheerio makes it easy to select, edit, and view DOM elements.
Setup
Our setup is pretty simple. We create a new folder and run this command inside that folder to create a package.json file. And add Nightmare and Cheerio from npm as our dependencies.
npm init -y
npm install nightmare cheerio --unsafe-perm=true
Now, require them in our index.js file
const Nightmare = require('nightmare');
const cheerio = require('cheerio');
Nightmare is similar to axios or any other request making library but what makes it odd is that it uses Electron under the cover, which is similar to PhantomJS but roughly twice as fast and more modern. Nightmare uses Javascript for handing/manipulating DOM through evaluate function which is complex to implement. So, we will use Cheerio for handling DOM content by fetching innerHTML through evaluate function and pass the content (innerHTML) to Cheerio which is easy, fast, and flexible to implement. Moreover, Nightmare also supports proxies, promises and async-await.
Scrape the static content
We have already scrapped the static content in the previous post, but before proceeding before, let’s do the same with Nightmare so we can have a wider vision and clear understanding of nightmare.
We are scraping data from the HackerNews website for which we need to make an HTTP request to get the website’s content and parse the data using cheerio.
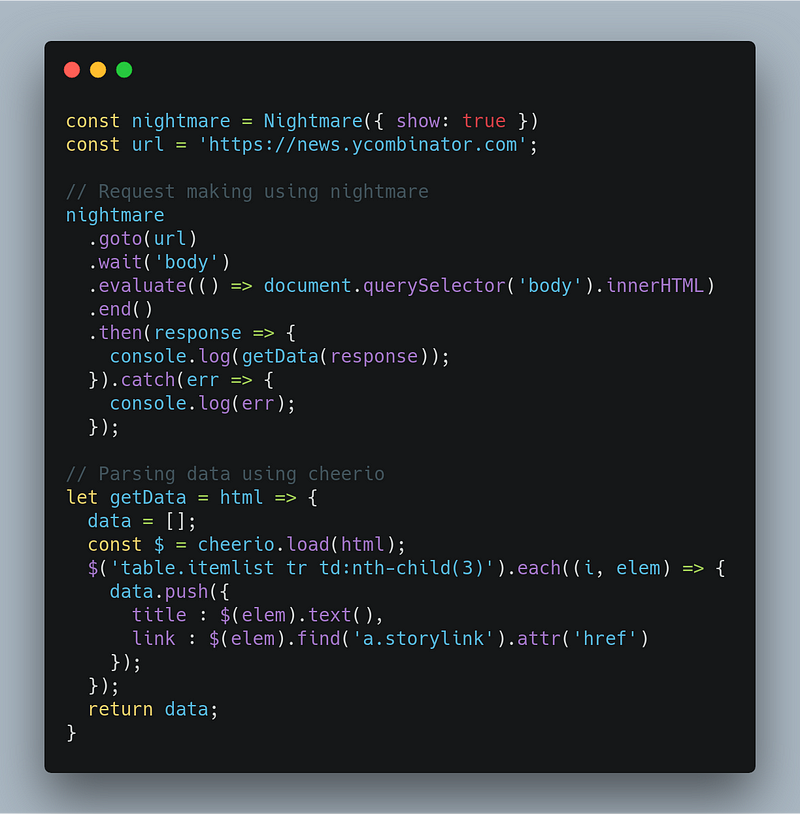
At the first line, we initialize the nightmare and set the show property true so we can monitor what the browser is doing on execution. We made a request to url through goto function and wait for the DOM to be rendered through wait function else it executes the next followup steps without rendering of the content completely. Once the body is loaded completely, we fetch the innerHTML using evaluate function and return the data. At last, we close the browser by calling end function.
You can use try/catch blocks but if you are using promises, .then()must be called after .end() to run the .end() task.
Scrape the dynamic content
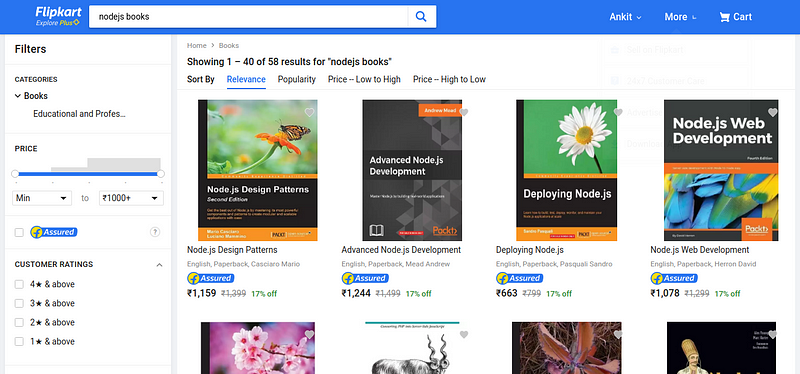
Now, we are familiar with nightmare and how it works. So, let’s try to scrape content from any website which uses javascript to render data. Apart from it, nightmare also interact with websites like we can make clicks, fill the forms, so let’s do this. We will scrape the products listed on the flipkart.com website but only those which appears in the search for nodejs books
For interacting with the webpage, we need to use click and type function. Let’s write some code.
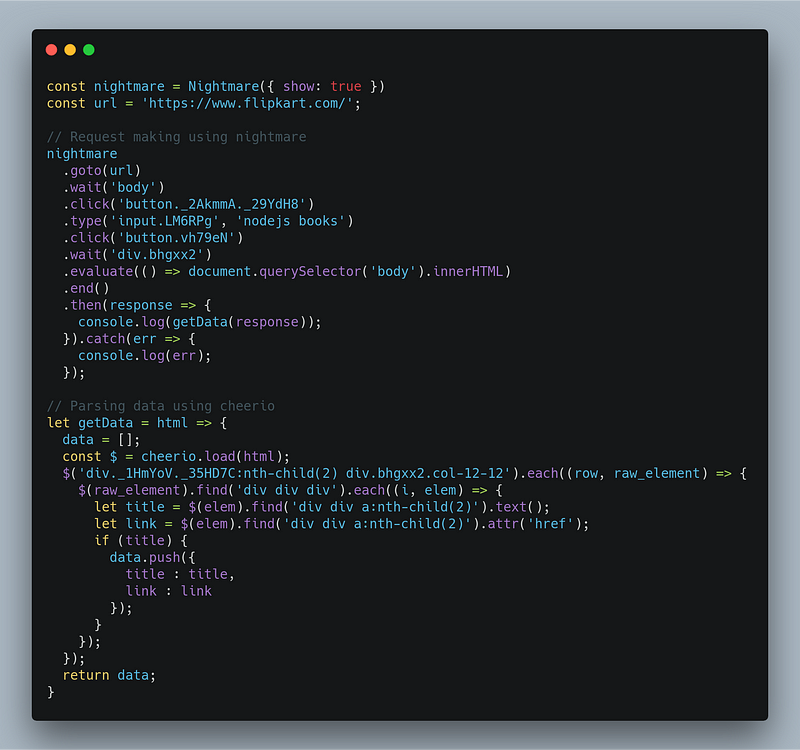
We are making a request to the Flipkart website and enter nodejs books in the search bar by selecting the appropriate HTML selector using type function. Selectors can be found by inspecting the HTML using Chrome DevTools. After that, we will click on the search button using click function. On clicking, It loads the requested content similar to any other browsers and we will fetch the innerHTML for scraping content as described in the second part using cheerio.
The Output will look like —
[
{
title: 'Node.js Design Patterns',
link: '/node-js-design-patterns/p/itmfbg2fhurfy97n?pid=9781785885587&lid=LSTBOK9781785885587OWNSQH&marketplace=FLIPKART&srno=s_1_1&otracker=search&fm=SEARCH&iid=1b09be55-0fad-44c8-a8ad-e38656f3f1b0.9781785885587.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
{
title: 'Advanced Node.js Development',
link: '/advanced-node-js-development/p/itmf4eg8asapzfeq?pid=9781788393935&lid=LSTBOK9781788393935UKCC4O&marketplace=FLIPKART&srno=s_1_2&otracker=search&fm=SEARCH&iid=b7ec6a1b-4e79-4117-9618-085b894a11dd.9781788393935.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
{
title: 'Deploying Node.js',
link: '/deploying-node-js/p/itmehyfmeqdbxwg5?pid=9781783981403&lid=LSTBOK9781783981403BYQFE4&marketplace=FLIPKART&srno=s_1_3&otracker=search&fm=SEARCH&iid=7824aa08-f590-4b8d-96ec-4df08cc1a4bb.9781783981403.SEARCH&ppt=Homepage&ppn=Homepage&ssid=dsiscm68uo0000001547989841622&qH=ecbb3518fc5ee1c0'
},
.
.
]
Now we have an array of JavaScript Object containing the title and links of the products(books) from the Flipkart website. In this way, we can scrape the data from any dynamic websites.
Conclusion
In this article, we first understood what is dynamic websites and how we can scrape data using nightmare and cheerio regardless of the type of website. The code is available in this Github Repo. Feel free to contribute and open issues.
*Originally published by Ankit Jain at *https://blog.bitsrc.io
Learn More
☞ The Complete Node.js Developer Course (2nd Edition)
☞ GraphQL: Learning GraphQL with Node.Js
☞ Angular (Angular 2+) & NodeJS - The MEAN Stack Guide
☞ Beginner Full Stack Web Development: HTML, CSS, React & Node
☞ Node with React: Fullstack Web Development
☞ MERN Stack Front To Back: Full Stack React, Redux & Node.js
#node-js #web-development