Even though Big data is in the mainstream of operations as of 2020, there are still potential issues or challenges the researchers can address. Some of these issues overlap with the data science field. In this article, the top 20 interesting latest research problems in the combination of big data and data science are covered based on my personal experience (with due respect to the Intellectual Property of my organizations) and the latest trends in these domains [1,2]. These problems are covered under 5 different categories, namely
Core Big data area to handle the scale
Handling Noise and Uncertainty in the data
Security and Privacy aspects
Data Engineering
Intersection of Big data and Data science
The article also covers a research methodology to solve specified problems and top research labs to follow which are working in these areas.
I encourage researchers to solve applied research problems which will have more impact on society at large. The reason to stress this point is that we are hardly analyzing 1% of the available data. On the other hand, we are generating terabytes of data every day. These problems are not very specific to a domain and can be applied across the domains.
Let me first introduce 8 V’s of Big data (based on an interesting article from Elena), namely Volume, Value, Veracity, Visualization, Variety, Velocity, Viscosity, and Virality. If we closely look at the questions on individual V’s in Fig 1, they trigger interesting points for the researchers. Even though they are business questions, there are underlying research problems. For instance, 02-Value: “Can you find it when you most need it?” qualifies for analyzing the available data and giving context-sensitive answers when needed.
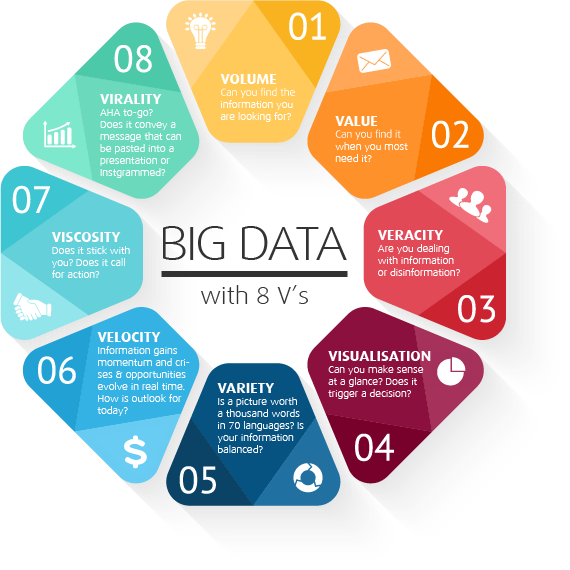
Fig 1: 8V’s of Big data Courtesy: Elena
Having understood the 8V’s of big data, let us look into details of research problems to be addressed. _General big data research topics _[3]are in the lines of:
- Scalability — Scalable Architectures for parallel data processing
- Real-time big data analytics — Stream data processing of text, image, and video
- Cloud Computing Platforms for Big Data Adoption and Analytics — Reducing the cost of complex analytics in the cloud
- Security and Privacy issues
- Efficient storage and transfer
- How to efficiently model uncertainty
- Graph databases
- Quantum computing for Big Data Analytics
Next, let me cover some of the specific research problems across the five listed categories mentioned above.
_The problems related to _core big data area of handling the scale:-
- Scalable architectures for parallel data processing:
Hadoop or Spark kind of environment is used for offline or online processing of data. The industry is looking for scalable architectures to carry out parallel data processing of big data. There is a lot of progress in recent years, however, there is a huge potential to improve performance.
2._ Handling real-time video analytics in a distributed cloud:_
With the increased accessibility to the internet even in developing countries, videos became a common medium of data exchange. There is a role of telecom infrastructure, operators, deployment of the Internet of Things (IoT), and CCTVs in this regard. Can the existing systems be enhanced with low latency and more accuracy? Once the real-time video data is available, the question is how the data can be transferred to the cloud, how it can be processed efficiently both at the edge and in a distributed cloud?
3. Efficient graph processing at scale:
Social media analytics is one such area that demands efficient graph processing. The role of graph databases in big data analytics is covered extensively in the reference article [4]. Handling efficient graph processing at a large scale is still a fascinating problem to work on.
_The research problems to _handle noise and uncertainty in the data:-
4. Identify fake news in near real-time:
This is a very pressing issue to handle the fake news in real-time and at scale as the fake news spread like a virus in a bursty way. The data may come from Twitter or fake URLs or WhatsApp. Sometimes it may look like an authenticated source but still may be fake which makes the problem more interesting to solve.
5. Dimensional Reduction approaches for large scale data:
One can extend the existing approaches of dimensionality reduction to handle large scale data or propose new approaches. This also includes visualization aspects. One can use existing open-source contributions to start with and contribute back to the open-source.
6. Training / Inference in noisy environments and incomplete data:
Sometimes, one may not get a complete distribution of the input data or data may be lost due to a noisy environment. Can the data be augmented in a meaningful way by oversampling, Synthetic Minority Oversampling Technique (SMOTE), or using Generative Adversarial Networks (GANs)? Can the augmentation help in improving the performance? How one can train and infer is the challenge to be addressed.
7. Handling uncertainty in big data processing:
There are multiple ways to handle the uncertainty in big data processing[4]. This includes sub-topics such as how to learn from low veracity, incomplete/imprecise training data. How to handle uncertainty with unlabeled data when the volume is high? We can try to use active learning, distributed learning, deep learning, and fuzzy logic theory to solve these sets of problems.
The research problems in the security****_and privacy _[5] area:-
8. Anomaly Detection in Very Large Scale Systems:
The anomaly detection is a very standard problem but it is not a trivial problem at a large scale in real-time. The range of application domains includes health care, telecom, and financial domains.
9. Effective anonymization of sensitive fields in the large scale systems:
Let me take an example from Healthcare systems. If we have a chest X-ray image, it may contain PHR (Personal Health Record). How one can anonymize the sensitive fields to preserve the privacy in a large scale system in near real-time? This can be applied to other fields as well primarily to preserve privacy.
10. Secure federated learning with real-world applications:
Federated learning enables model training on decentralized data. It can be adopted where the data cannot be shared due to regulatory / privacy issues but still may need to build the models locally and then share the models across the boundaries. Can we still make the federated learning work at scale and make it secure with standard software/hardware-level security is the next challenge to be addressed. Interested researchers can explore further information from RISELab of UCB in this regard.
11. Scalable privacy preservation on big data:
Privacy preservation for large scale data is a challenging research problem to work on as the range of applications varies from the text, image to videos. The difference in country/region level privacy regulations will make the problem more challenging to handle.
The research problems related to data engineering aspects:-
#data-science #top-research-problems #big-data #data-challenge #data analysis #data analysis