Reinforcement learning (RL) is surely a rising field, with the huge influence from the performance of AlphaZero (the best chess engine as of now). RL is a subfield of machine learning that teaches agents to perform in an environment to maximize rewards overtime.
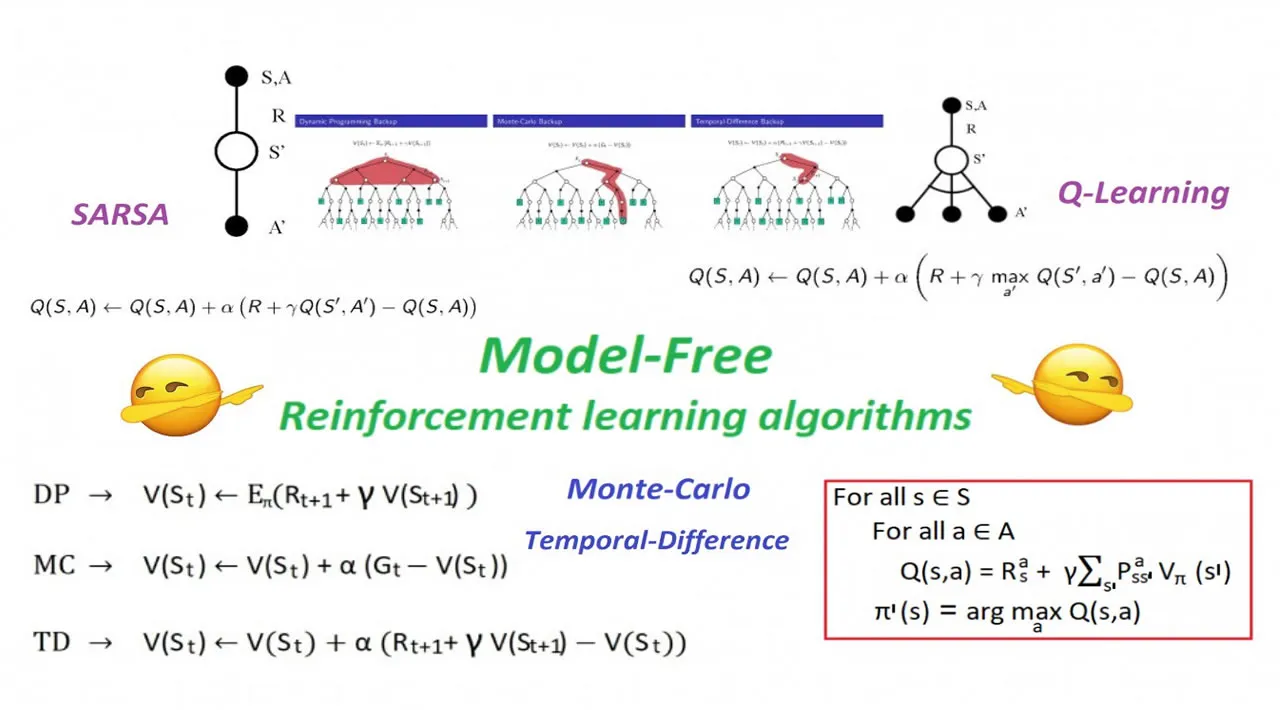
Among RL’s model-free methods is temporal difference (TD) learning, with SARSA and Q-learning (QL) being two of the most used algorithms. I chose to explore SARSA and QL to highlight a subtle difference between on-policy learning and off-learning, which we will discuss later in the post.
This post assumes you have basic knowledge of the agent, environment, action, and rewards within RL’s scope. A brief introduction can be found here.
The outline of this post include:
- Temporal difference learning (TD learning)
- Parameters
- QL & SARSA
- Comparison
- Implementation
- Conclusion
We will compare these two algorithms via the CartPole game implementation. This post’s code can be found here :QL code ,SARSA code , and the fully functioning code . (the fully-functioning code has both algorithms implemented and trained on cart pole game)
The TD learning will be a bit mathematical, but feel free to skim through and jump directly to QL and SARSA.
#reinforcement-learning #artificial-intelligence #machine-learning #deep-learning #learning