A simple yet comprehensive approach to the concepts
Convolutional Neural Networks
Artificial intelligence has seen a tremendous growth over the last few years, The gap between machines and humans is slowly but steadily decreasing. One important difference between humans and machines is (or rather was!) with regards to human’s perception of images and sound.How do we train a machine to recognize images and sound as we do?
At this point we can ask ourselves a few questions!!!
How would the machines perceive images and sound ?
How would the machines be able to differentiate between different images for example say between a cat and a dog?
Can machines identify and differentiate between different human beings for example lets say differentiate a male from a female or identify Leonardo Di Caprio or Brad Pitt by just feeding their images to it?
Let’s attempt to find out!!!
The Colour coding system:
Lets get a basic idea of what the colour coding system for machines is
RGB decimal system: It is denoted as rgb(255, 0, 0). It consists of three channels representing RED , BLUE and GREEN respectively . RGB defines how much red, green or blue value you’d like to have displayed in a decimal value somewhere between 0, which is no representation of the color, and 255, the highest possible concentration of the color. So, in the example rgb(255, 0, 0), we’d get a very bright red. If we wanted all green, our RGB would be rgb(0, 255, 0). For a simple blue, it would be rgb(0, 0, 255).As we know all colours can be obtained as a combination of Red , Green and Blue , we can obtain the coding for any colour we want.
Gray scale: Gray scale consists of just 1 channel (0 to 255)with 0 representing black and 255 representing white. The colors in between represent the different shades of Gray.
Computers ‘see’ in a different way than we do. Their world consists of only numbers.
Every image can be represented as 2-dimensional arrays of numbers, known as pixels.
But the fact that they perceive images in a different way, doesn’t mean we can’t train them to recognize patterns, like we do. We just have to think of what an image is in a different way.

Now that we have a basic idea of how images can be represented , let us try and understand The architecture of a CNN
CNN architecture
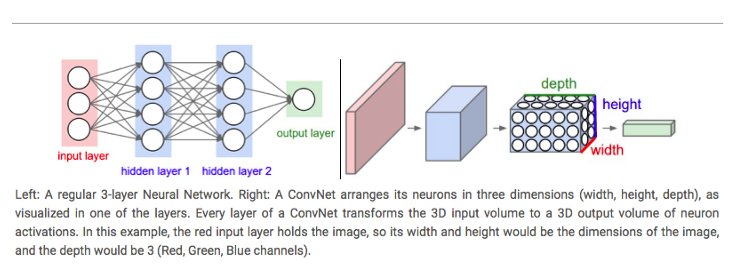
Convolutional Neural Networks have a different architecture than regular Neural Networks. Regular Neural Networks transform an input by putting it through a series of hidden layers. Every layer is made up of a set of neurons, where each layer is fully connected to all neurons in the layer before. Finally, there is a last fully-connected layer — the output layer — that represent the predictions.
Convolutional Neural Networks are a bit different. First of all, the layers are organised in 3 dimensions: width, height and depth. Further, the neurons in one layer do not connect to all the neurons in the next layer but only to a small region of it. Lastly, the final output will be reduced to a single vector of probability scores, organized along the depth dimension
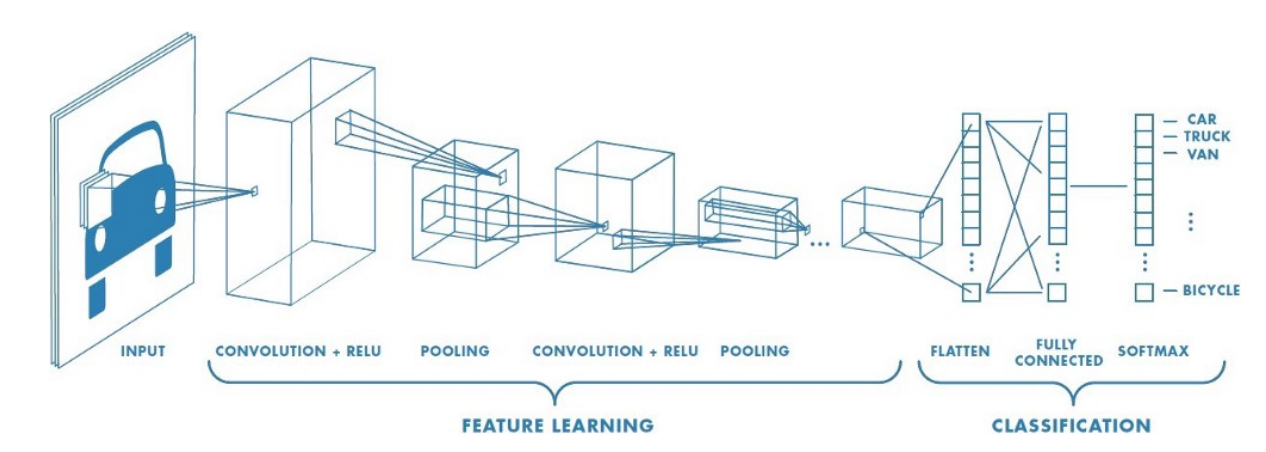
A typical CNN architecture
As can be seen above CNNs have two components:
- The Hidden layers/Feature extraction part
In this part, the network will perform a series of **convolutions **and pooling operations during which the features are detected. If you had a picture of a tiger , this is the part where the network would recognize the stripes , 4 legs , 2 eyes , one nose , distinctive orange colour etc.
- The Classification part
Here, the fully connected layers will serve as a classifier on top of these extracted features. They will assign a** probability** for the object on the image being what the algorithm predicts it is.
Before we proceed any further we need to understand what is “convolution”, we will come back to the architecture later:
What do we mean by the “convolution” in Convolutional Neural Networks?
Let us decode!!!
#convolutional-neural-net #convolution #computer-vision #neural networks